MySQL教程(二)—— 概述和SQL语法
一,MySQL基础
1.1 什么是数据库
数据库(DataBase) 是按照数据结构来组织、存储和管理数据的仓库
数据库是一个数据的集合。
其本质是一个文件系统,以文件的方式,将数据保存在电脑上
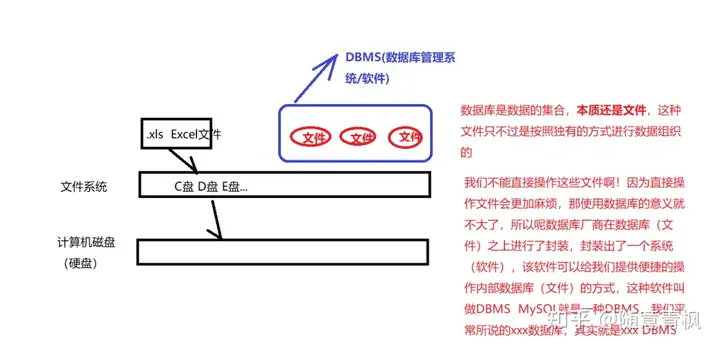
1.2 为什么要使用数据库
数据存储方式的比较
1)内存
优点:速度快
缺点:容量有限,不能够永久保存,数据是临时状态的
2)文件(Excel)
优点:数据是可以永久保存的
缺点:少量数据直接打开获取数据,大量数据使用程序IO流操作文件, 不方便;同一时间多人操作某一个文件也可能出现问题
3)数据库
优点: 海量数据存储,提供不错的查询效率 ,数据可以永久保存 ,方便存储和管理数据 ,使用统一的方式操作数据库
缺点 :占用资源(重型武器) ,有些数据库需要付费
我们把它和excel进行对比一下

4)表
表是包含数据库中所有数据的数据库对象,由行和列组成(二维表格模型,就类似于Sheet),用于组织和存储数据。
5)字段
表中每一列称为一个字段,字段有自己的属性,如字段类型、字段大小等。其中,字段类型是字段最重要的属性,它决定了字段能够存储哪种数据。
和Excel不同,这里针对列(字段要求比较严格),该列存储什么类型数据,长度多少都应该提前(建表的时候)进行定义
6)索引
索引是一个单独的、物理的数据库结构。它是依赖于表建立,在数据库中使用索引,无须对整个表进行扫描,就可以找到需要的数据。
7)视图
视图是从一张或多张表中导出的表(也称虚拟表),是用户查看数据表中数据的一种方式。
1.3 SQL分类
我们学的主要也就是这些
1) 数据查询语言(DQL:Data Query Language):
其语句,也称为“数据检索语句”,用以从表中获得数据,确定数据怎样在应用程序给出。保留字SELECT是DQL(也是所有SQL)用得最多的动词,其他DQL常用的保留字有WHERE,ORDER BY,GROUP BY和HAVING。这些DQL保留字常与其他类型的SQL语句一起使用。
专门用于查询数据:代表指令为select/show
2) 数据操作语言(DML:Data Manipulation Language):
其语句包括动词INSERT,UPDATE和DELETE。它们分别用于添加,修改和删除表中的行。也称为动作查询语言。
专门用于写数据:代表指令为insert,update和delete
3)事务处理语言(TPL):
它的语句能确保被DML语句影响的表的所有行及时得以更新。TPL语句包括BEGIN TRANSACTION,COMMIT和ROLLBACK。(不是所有的关系型数据库都提供事务安全处理)
专门用于事务安全处理:transaction
4)数据控制语言(DCL):
它的语句通过GRANT或REVOKE获得许可,确定单个用户和用户组对数据库对象的访问。某些RDBMS可用GRANT或REVOKE控制对表单个列的访问。
专门用于权限管理:代表指令为grant和revoke
5) 数据定义语言(DDL):
其语句包括动词CREATE和DROP。在数据库中创建新表或删除表(CREAT TABLE 或 DROP TABLE);为表加入索引等。DDL包括许多与人数据库目录中获得数据有关的保留字。它也是动作查询的一部分。
专门用于结构管理:代表指令create和drop(alter)
二, MySQL数据库
2.1 Mysql存储引擎
存储引擎是MySQL数据库的核心、心脏、发动机,它决定了数据如何存储,查询的时候如
何搜索数据,索引如何创建等等
MySQL 5.1版本之前默认的存储引擎是MyISAM,之后默认是InnoDB
什么是存储引擎?
存储引擎其实就是对于数据库文件的一种存取机制,如何实现存储数据,如何为存储的数据建立索引以及如何更新,查询数据等技术实现的方法。
常用存储引擎
InnoDB:
1)事务处理、回滚、崩溃修复能力和多版本并发控制
2)自增长AUTO_INCREMENT
3)外键(FOREIGN KEY)
InnoDB的优势在于提供了良好的事务处理、崩溃修复能力和并发控制。缺点是读写效率较差,
占用的数据空间相对较大。
MyISAM:
MyISAM的优势在于占用空间小,处理速度快。缺点是不支持事务的完整性和并发性。
Memory:
1)数据全部放在内存中
2)哈希索引
注意,MEMORY用到的很少,因为它是把数据存到内存中,如果内存出现异常就会影响数据。
如果重启或者关机,所有数据都会消失。因此,基于MEMORY的表的生命周期很短,一般是一
次性的。
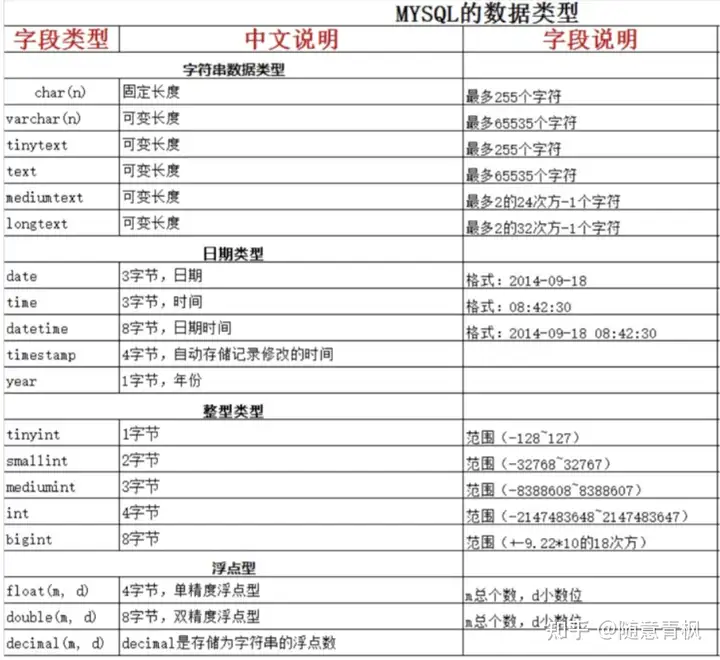
2.2 Mysql数据类型
MySQL数据库中的每一条数据都有其数据类型,主要分为数值型,字符串型和日期时间型三个大类。
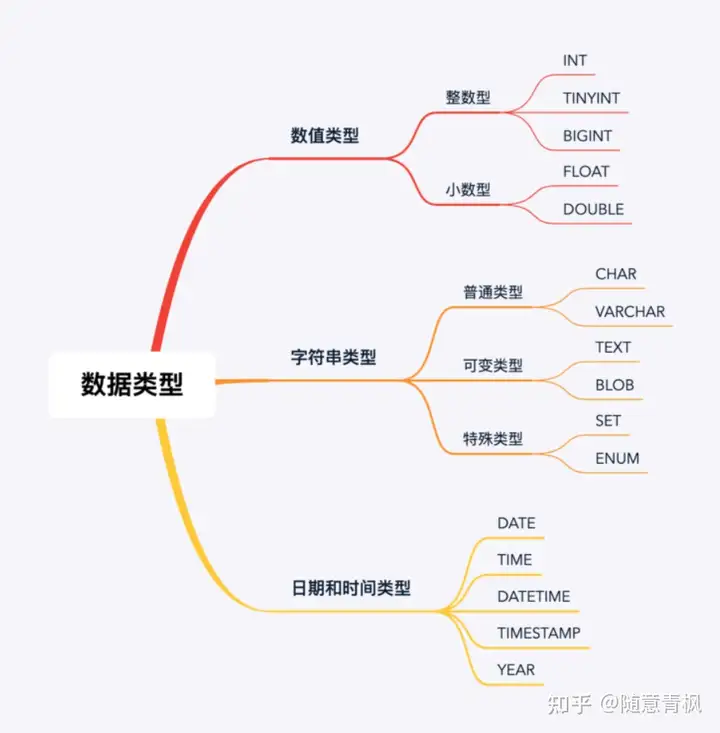
数值类型
整数类型
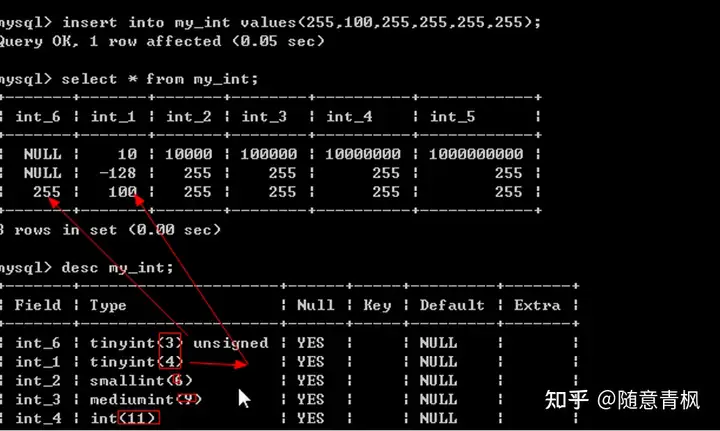
1)Tinyint
迷你整形,系统采用一个字节来保存的整形:一个字节 = 8位,最大能表示的数值是0-255
2)Smallint
小整形,系统采用两个字节来保存的整形:能表示0-65535之间
3)Mediumint
中整形,采用三个字节来保存数据。
4)Int
整形(标准整形),采用四个字节来保存数据。
5)Bigint
大整形,采用八个字节来保存数据。
1、 创建数据表
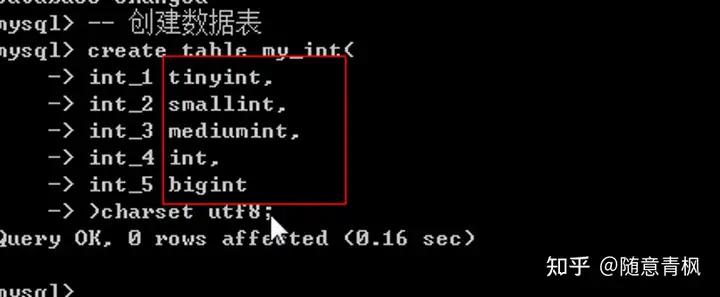
2、 插入合理数据
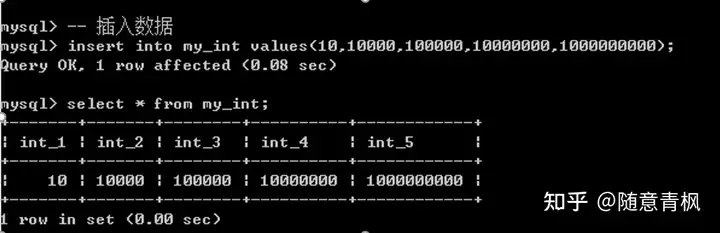
3、 插入错误数据(超出对应的数据范围)

4、 错误原因:并不是说tinyint没有这么大的空间,而是因为mysql默认的为整形增加负数。
实际表示的区间为-128,127
实际应用中,应该根据对应的数据的范围来选定对应的整形类型:通常使用的比较多的TINYINT和int。
无符号标识设定
无符号:表示存储的数据在当前字段中,没有负数(只有正数,区间为0-255)
基本语法:在类型之后加上一个 unsigned
小数类型
专门用来存储小数的
在Mysql中将小数类型又分为两类:浮点型和定点型
1)浮点型
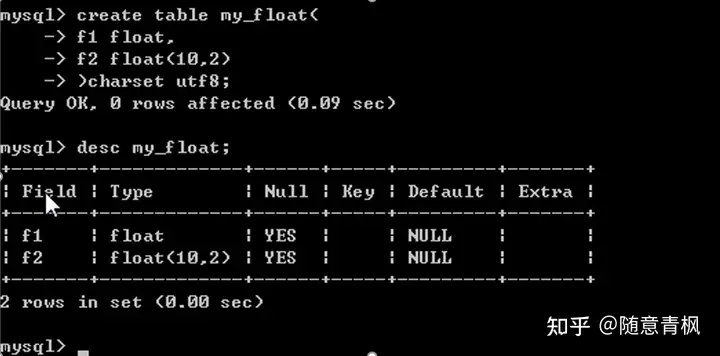
Float
Float又称之为单精度类型:系统提供4个字节用来存储数据,但是能表示的数据范围比整型大的多,大概是10^38;只能保证大概7个左右的精度(如果数据在7位数以内,那么基本是准确的,但是如果超过7位数,那么就是不准确的)
基本语法
Float:表示不指定小数位的浮点数
Float(M,D):表示一共存储M个有效数字,其中小数部分占D位
Float(10,2):整数部分为8位,小数部分为2位
1、 创建一个数据表保存浮点数据
2、 存入数据:合法数据
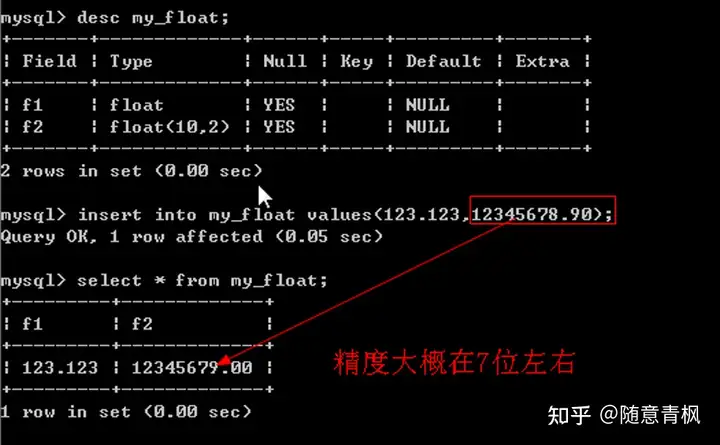
注意:如果数据精度丢失,那么浮点型是按照四舍五入的方式进行计算
3、 插入数据,超出大小

4、 数据长度刚好满足条件,但是会超出精度
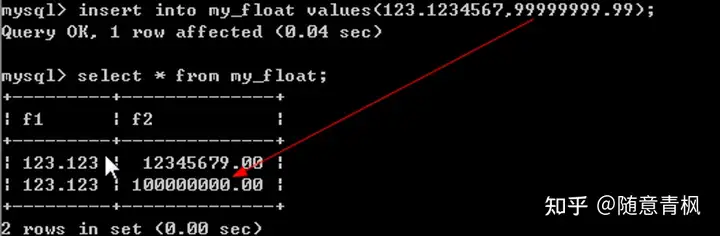
说明:用户不能插入数据直接超过指定的整数部分长度,但是如果是系统自动进位导致,系统可以承担。
5、浮点数可以采用科学计数法来存储数据
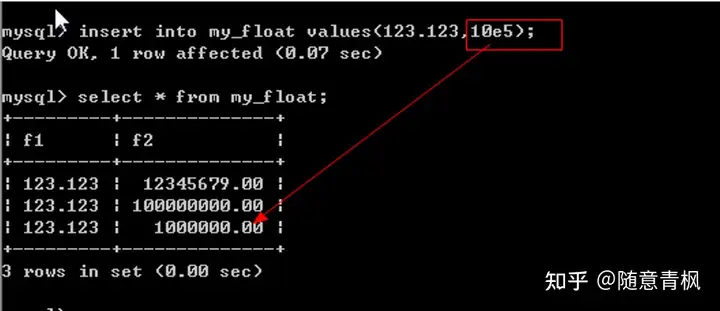
浮点数的应用:通常是用来保存一些数量特别大,大到可以不用那么精确的数据。
2)Double
Double又称之为双精度:系统用8个字节来存储数据,表示的范围更大,10^308次方,但是精度也只有15位左右。
定点数(比较常用的)
定点数:能够保证数据精确的小数(小数部分可能不精确,超出长度会四舍五入),整数部分一定精确
Decimal
Decimal定点数:系统自动根据存储的数据来分配存储空间,每大概9个数就会分配四个字节来进行存储,同时小数和整数部分是分开的。
Decimal(M,D):M表示总长度,最大值不能超过65,D代表小数部分长度,最长不能超过30。
定点数的应用:如果涉及到钱的时候有可能使用定点数
字符串类型
短文本:char varchar
CHAR(M) - 固定长度的字符串是以长度为1到255之间个字符长度(例如:CHAR(5)),存储右空格
填充到指定的长度。 限定长度不是必需的,它会默认为1。 char(5)内存空间会浪费,性别:男/女 char(1)
VARCHAR(M) - 可变长度的字符串是以长度为1到255之间字符数(高版本的MySQL超过255); 例
如: VARCHAR(25). 创建VARCHAR类型字段时,必须定义长度。 5 10 12 节省内存空间
可变类型
BLOB 或 TEXT - 字段的最大长度是65535个字符。 BLOB是“二进制大对象”,并用来存储大的二
进制数据,如图像或其他类型的文件。定义为TEXT文本字段还持有大量的数据; 两者之间的区别
是,排序和比较上存储的数据,BLOB大小写敏感,而TEXT字段不区分大小写。不用指定BLOB
或TEXT的长度。
日期和时间类型
DATE - 以YYYY-MM-DD格式的日期,在1000-01-01和9999-12-31之间。 例如,1973年12月30
日将被存储为1973-12-30。
DATETIME - 日期和时间组合以YYYY-MM-DD HH:MM:SS格式,在1000-01-01 00:00:00 到
9999-12-31 23:59:59之间。例如,1973年12月30日下午3:30,会被存储为1973-12-30 15:30:00。
TIMESTAMP - 1970年1月1日午夜之间的时间戳,到2037的某个时候。这看起来像前面的
DATETIME格式,无需只是数字之间的连字符; 1973年12月30日下午3点30分将被存储为
19731230153000(YYYYMMDDHHMMSS)。
TIME - 存储时间在HH:MM:SS格式。
YEAR(M) - 以2位或4位数字格式来存储年份。如果长度指定为2(例如YEAR(2)),年份就可以为
1970至2069(70〜69)。如果长度指定为4,年份范围是1901-2155,默认长度为4。
MySQL数值类型汇总
整型
| 类型名称 | 取值范围 | 大小 |
|---|---|---|
| TINYINT | -128〜127 | 1个字节 |
| SMALLINT | -32768〜32767 | 2个宇节 |
| MEDIUMINT | -8388608〜8388607 | 3个字节 |
| INT (INTEGHR) | -2147483648〜2147483647 | 4个字节 |
| BIGINT | -9223372036854775808〜9223372036854775807 | 8个字节 |
无符号在数据类型后加 unsigned 关键字。
浮点型
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| FLOAT | 单精度浮点数 | 4 个字节 |
| DOUBLE | 双精度浮点数 | 8 个字节 |
| DECIMAL (M, D),DEC | 压缩的“严格”定点数 | M+2 个字节 |
日期和时间
| 类型名称 | 日期格式 | 日期范围 | 存储需求 |
|---|---|---|---|
| YEAR | YYYY | 1901 ~ 2155 | 1 个字节 |
| TIME | HH:MM:SS | -838:59:59 ~ 838:59:59 | 3 个字节 |
| DATE | YYYY-MM-DD | 1000-01-01 ~ 9999-12-3 | 3 个字节 |
| DATETIME | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | 8 个字节 |
| TIMESTAMP | YYYY-MM-DD HH:MM:SS | 1980-01-01 00:00:01 UTC ~ 2040-01-19 03:14:07 UTC | 4 个字节 |
字符串
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| CHAR(M) | 固定长度非二进制字符串 | M 字节,1<=M<=255 |
| VARCHAR(M) | 变长非二进制字符串 | L+1字节,在此,L< = M和 1<=M<=255 |
| TINYTEXT | 非常小的非二进制字符串 | L+1字节,在此,L<2^8 |
| TEXT | 小的非二进制字符串 | L+2字节,在此,L<2^16 |
| MEDIUMTEXT | 中等大小的非二进制字符串 | L+3字节,在此,L<2^24 |
| LONGTEXT | 大的非二进制字符串 | L+4字节,在此,L<2^32 |
| ENUM | 枚举类型,只能有一个枚举字符串值 | 1或2个字节,取决于枚举值的数目 (最大值为65535) |
| SET | 一个设置,字符串对象可以有零个或 多个SET成员 | 1、2、3、4或8个字节,取决于集合 成员的数量(最多64个成员) |
二进制类型
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| BIT(M) | 位字段类型 | 大约 (M+7)/8 字节 |
| BINARY(M) | 固定长度二进制字符串 | M 字节 |
| VARBINARY (M) | 可变长度二进制字符串 | M+1 字节 |
| TINYBLOB (M) | 非常小的BLOB | L+1 字节,在此,L<2^8 |
| BLOB (M) | 小 BLOB | L+2 字节,在此,L<2^16 |
| MEDIUMBLOB (M) | 中等大小的BLOB | L+3 字节,在此,L<2^24 |
| LONGBLOB (M) | 非常大的BLOB | L+4 字节,在此,L<2^32 |
注意:MySql中的 char类型与 varchar类型,区别在于:
char类型是固定长度的: 根据定义的字符串长度分配足够的空间。
varchar类型是可变长度的: 只使用字符串长度所需的空间

三, SQL语句操作详解
我们需要学到的语句就是上面sql分类的那几类定义的语言
DML语句(Data Manipulation Language 数据操纵语言)
针对table数据表中数据的增删改,使用DML
DQL语句(Data Query Language 数据查询语言)
针对table数据表中数据的查询操作,使用DQL
DCL语句(Data Control Language 数据控制语言)
事务的提交/回滚等
3.1 SQL通用语法
SQL语句可以单行 或者 多行书写,以分号结尾 ; (Sqlyog中可以不用写分号)
可以使用空格和缩进来增加语句的可读性。
MySql中使用SQL不区分大小写,一般关键字大写,数据库名 表名列名 小写。
3.2. 注释方式
1 | # show databases; 单行注释 |
3.3 DDL操作数据库
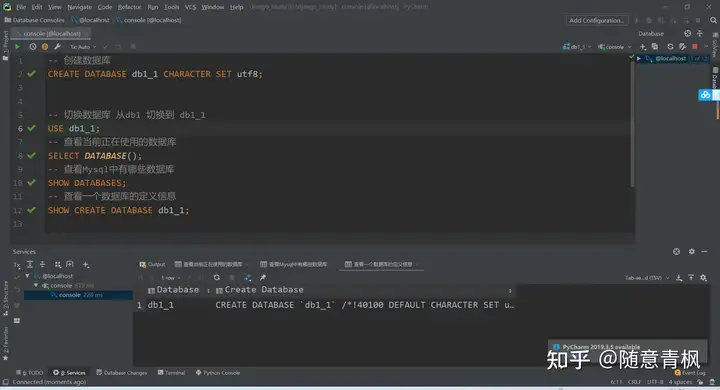
1)创建数据库
create database 数据库名;说明:创建指定名称的数据库。
create database 数据库名 characterset 字符集;说明:创建指定名称的数据库,并且指定字符集(一
般都指定utf8)
1 | /* |
2) 查看/选择数据库
代码示例
1 | -- 切换数据库 从db1 切换到 db1_1 |
3)修改数据库
修改数据库字符集

1 | -- 将数据库db1 的字符集 修改为 utf8 |
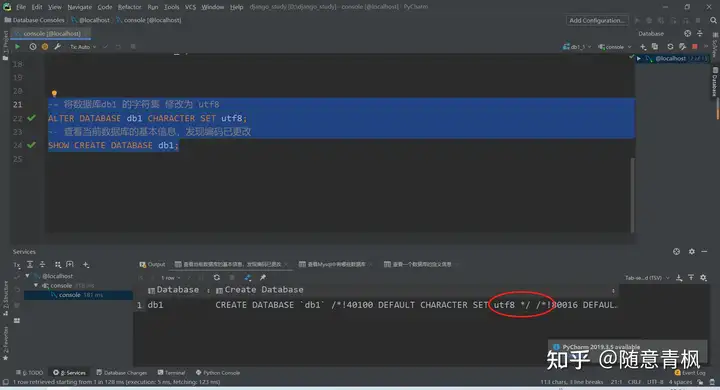
4) 删除数据库

1 | -- 删除某个数据库 |
3.4 DDL 操作数据表
1) 创建表
字段类型就是我们上面介绍的mysql数据类型

需求1: 创建商品分类表

1 | -- 切换到数据库 db1 |
需求2: 创建测试表

1 | -- 创建测试表 |
需求3: 快速创建一个表结构相同的表(复制表结构)

1 | -- 创建一个表结构与 test1 相同的 test2表 |
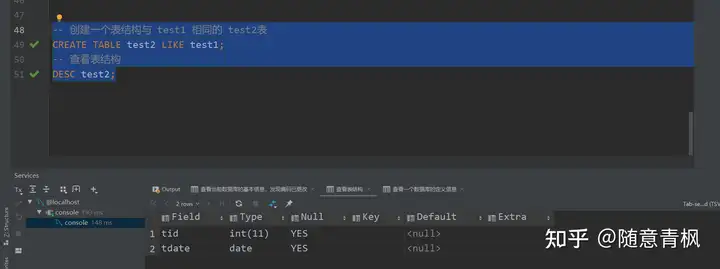
2 )查看表

1 | -- 查看当前数据库中的所有表名 |
3) 删除表

1 | -- 直接删除 test1 表 |
4) 修改表
①修改表名

需求: 将category表 改为 category1
1 | RENAME TABLE category TO category1; |
②向表中添加列, 关键字 ADD

需求: 为分类表添加一个新的字段为 分类描述 cdesc varchar(20)
1 | # 为分类表添加一个新的字段为 分类描述 cdesc varchar(20) |
③修改表中列的 数据类型或长度 , 关键字 MODIFY

需求:对分类表的描述字段进行修改,类型varchar(50)
1 | ALTER TABLE category MODIFY cdesc VARCHAR(50); |
④.修改列名称 , 关键字 CHANGE

需求: 对分类表中的 desc字段进行更换, 更换为 description varchar(30)
1 | ALTER TABLE category CHANGE cdesc description VARCHAR(30); |
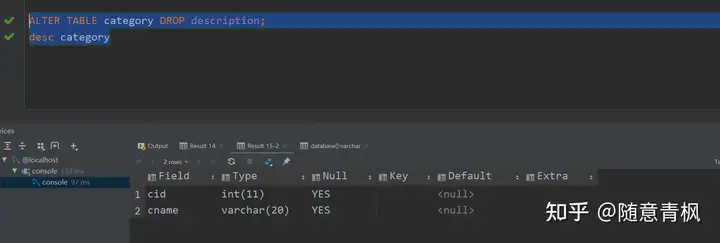
⑤删除列 ,关键字 DROP

需求: 删除分类表中description这列
1 | ALTER TABLE category DROP description; |
3.5 DML 操作表中数据(重点)
SQL中的DML 用于对表中的数据进行增删改操作
1)插入数据

①代码准备,创建一个学生表:

1 | # 创建学生表 |
②向 学生表中添加数据,3种方式
方式1: 插入全部字段, 将所有字段名都写出来
1 | INSERT INTO student (sid,sname,age,sex,address) VALUES(1,'孙悟 |
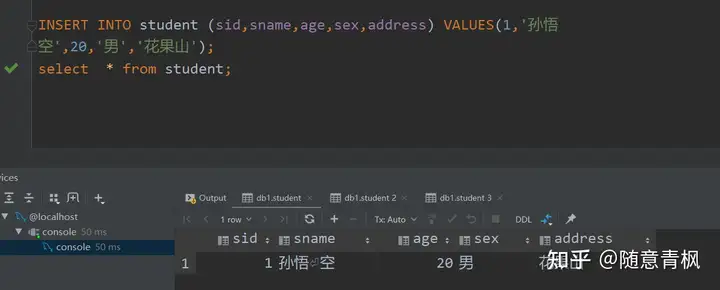
方式2: 插入全部字段,不写字段名
1 | INSERT INTO student VALUES(2,'孙悟饭',10,'男','地球'); |
方式3:插入指定字段的值
1 | INSERT INTO category (cname) VALUES('白骨精'); |


2) 更改数据
语法格式1:不带条件的修改
1 | update 表名 set 列名 = 值 |
语法格式2:带条件的修改
1 | update 表名 set 列名 = 值 [where 条件表达式:字段名 = 值 ] |
①不带条件修改,将所有的性别改为女(慎用!!)
1 | UPDATE student SET sex = '女'; |
②带条件的修改,将sid 为3的学生,性别改为男
1 | UPDATE student SET sex = '男' WHERE sid = 3; |
③一次修改多个列, 将sid为 2 的学员,年龄改为 20,地址改为 北京
1 | UPDATE student SET age = 20,address = '北京' WHERE sid = 2; |
3)删除数据

①删除 sid 为 1 的数据
1 | DELETE FROM student WHERE sid = 1; |
②删除所有数据
1 | DELETE FROM student; |
③如果要删除表中的所有数据,有两种做法
3.6 DQL 查询表中数据(重点)
1)准备数据
1 | #创建员工表 |
2) 简单查询
执行顺序
FROM –> WHERE –> GROUP BY –> HAVING –> SELECT –> ORDER BY
需求1: 查询emp中的 所有数据
1 | SELECT * FROM emp; -- 使用 * 表示所有列 |
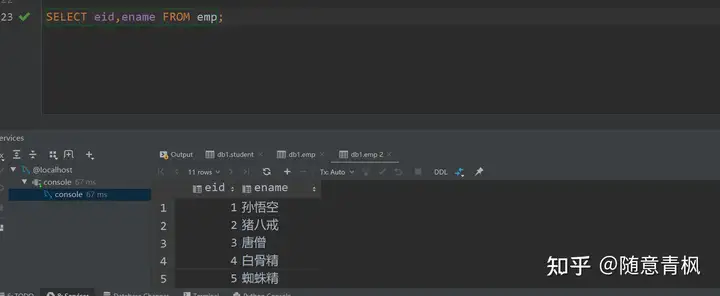
需求2: 查询emp表中的所有记录,仅显示id和name字段
1 | SELECT eid,ename FROM emp; |
需求3: 将所有的员工信息查询出来,并将列名改为中文
别名查询,使用关键字 as
1 | # 使用 AS关键字,为列起别名 |
需求4:查询一共有几个部门
使用去重关键字 distinct
1 | -- 使用distinct 关键字,去掉重复部门信息 |
需求5: 将所有员工的工资 +1000 元进行显示
运算查询 (查询结果参与运算)
1 | SELECT ename , salary + 1000 FROM emp; |
3)条件查询
如果查询语句中没有设置条件,就会查询所有的行信息,在实际应用中,一定要指定查询条件,对记
录进行过滤


比较运算符

逻辑运算符

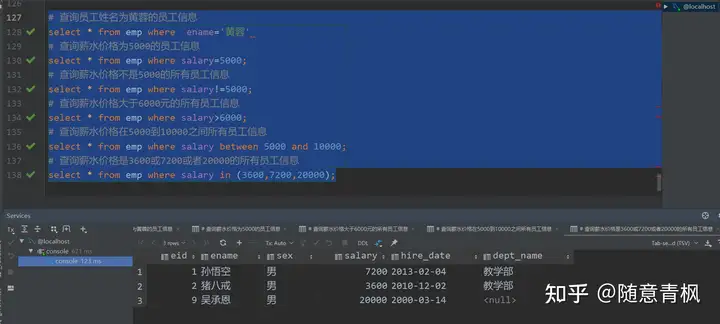
需求1:
1 | # 查询员工姓名为黄蓉的员工信息 |
需求2:
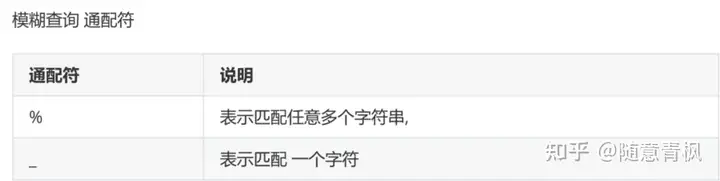
1 | # 查询含有'精'字的所有员工信息 |
四,mysql核心查询
排序 分组 聚合 多表查询 合并查询 子查询
4.1 单表查询
1)排序
通过 ORDER BY 子句,可以将查询出的结果进行排序(排序只是显示效果,不会影响真实数据)
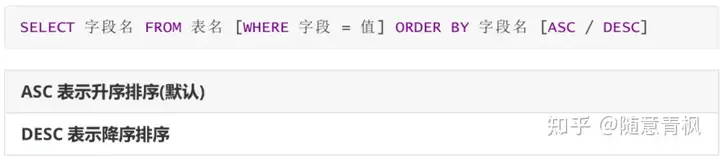
①单列排序
只按照某一个字段进行排序, 就是单列排序
需求1:
使用 salary 字段,对emp 表数据进行排序 (升序/降序)
1 | -- 默认升序排序 ASC |
②组合排序
同时对多个字段进行排序, 如果第一个字段相同 就按照第二个字段进行排序,以此类推
需求2:
在薪水排序的基础上,再使用id进行排序, 如果薪水相同就以id 做降序排序
1 | -- 组合排序 |
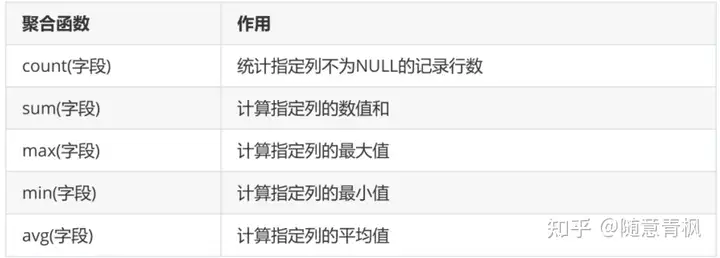
4.2 聚合函数
干嘛的?求员工最高工资/平均工资/工资总和,都是聚合函数来做的之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对某一列的值进行计算,然后返回一个单一的值(另外聚合函数会忽略null空
值。);
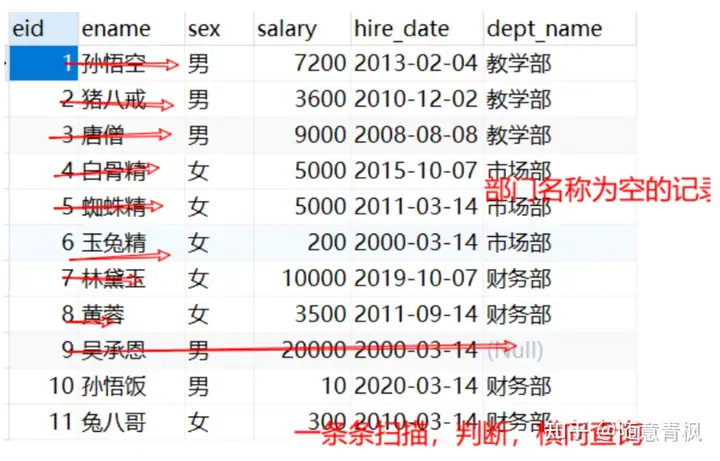
函数:方法,它封装了一些逻辑,比如给他一堆数据,特定函数可以返回最大值max(),avg()平
均值
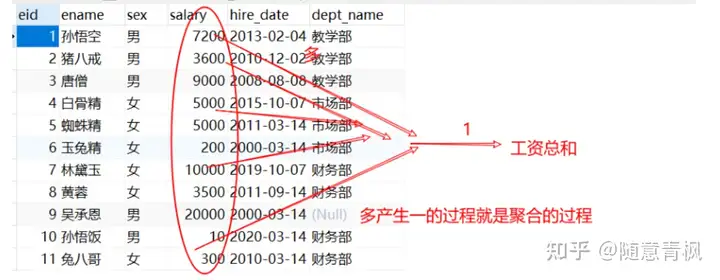
聚合,也称为聚合统计或者聚合查询,就需要使用select关键字,有select 就得有from xxx

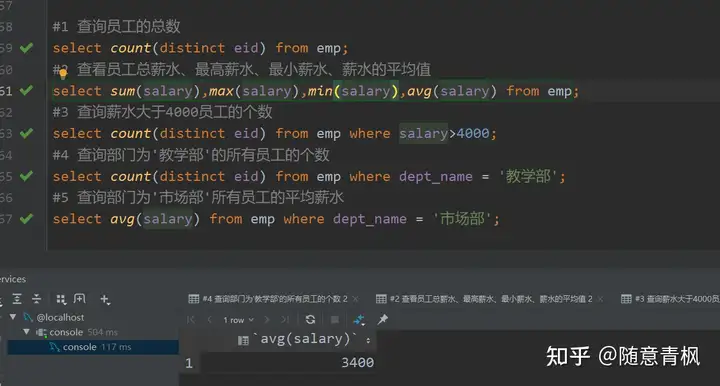
需求1:
1 | #1 查询员工的总数 |

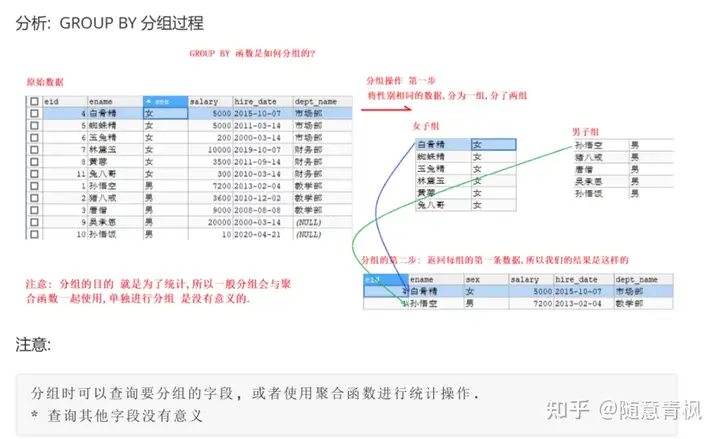
4.3 分组
分组往往和聚合函数一起时候,对数据进行分组,分完组之后在各个组内进行聚合统计分析
比如:求各个部门的员工数~
分组查询指的是使用 GROUP BY 语句,对查询的信息进行分组,相同数据作为一组

需求1: 通过性别字段 进行分组
1 | -- 按照性别进行分组操作 |
需求: 通过性别字段 进行分组,求各组的平均薪资
1 | SELECT sex, AVG(salary) FROM emp GROUP BY sex; |

需求2:
1 | #1.查询每个部门的平均薪资 |
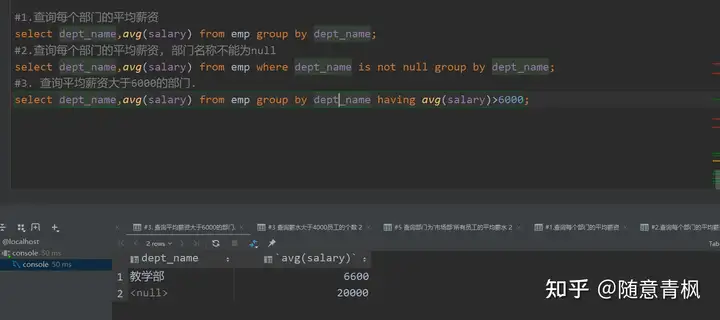
分析:
\1) 需要在分组后,对数据进行过滤,使用 关键字 having
\2) 分组操作中的having子语句,是用于在分组后对数据进行过滤的,作用类似于where条
件。
where 与 having的区别
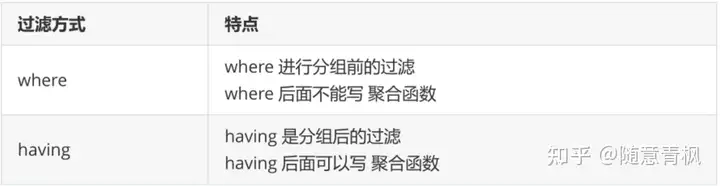
4.4 limit关键字
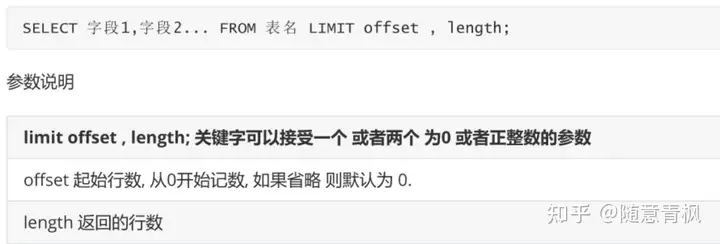
limit 关键字的作用
limit是限制的意思,用于 限制返回的查询结果的行数 (可以通过limit指定查询多少行数据)
limit 语法是 MySql的方言,用来完成分页
1 | # 查询emp表中的前 5条数据 |
五 mysql约束
SQL语句来创建数据库约束
1)约束的作用:
对表中的数据进行进一步的限制,从而保证数据的正确性、有效性、完整性.
违反约束的不正确数据,将无法插入到表中
注意:约束是针对字段的
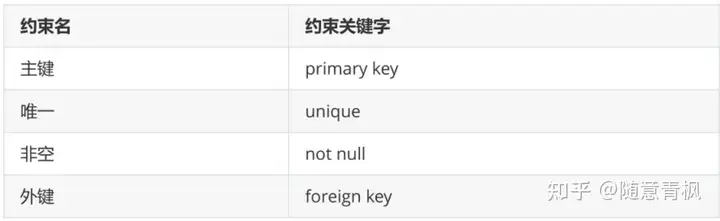
2)常见的约束
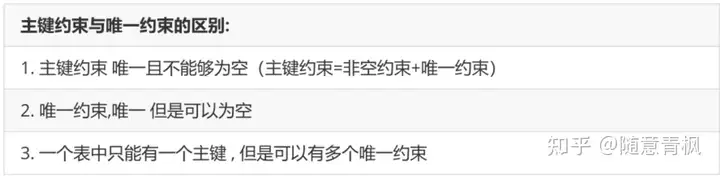
5.1 主键约束

1)添加主键约束

需求: 创建一个带主键的表
1 | # 方式1 创建一个带主键的表 |
DESC 查看表结构
测试主键的唯一性 非空性
1 | # 正常插入一条数据 |
\2) 哪些字段可以作为主键 ?
通常针对业务去设计主键,往往每张表都设计一个主键
主键是给数据库和程序使用的,跟最终的客户无关,所以主键没有意义没有关系,只要能够保证
不重复就好,
比如 身份证号列就可以作为主键.另外,如果没有和业务关联太大的可以设计为主键的列的话,我们在进行数据库设计的时候往往人为加一列作为主键列,习惯上起名为id,rid等
3)删除主键约束
删除 表中的主键约束 (了解)
1 | -- 使用DDL语句 删除表中的主键 |
4)主键的自增
注: 主键如果让我们自己添加很有可能重复,我们通常希望在每次插入新记录时,数据库自动生成
主键字段的值.

创建主键自增的表
1 | -- 创建主键自增的表 |
添加数据 观察主键的自增
1 | INSERT INTO emp2(ename,sex) VALUES('张三','男'); |
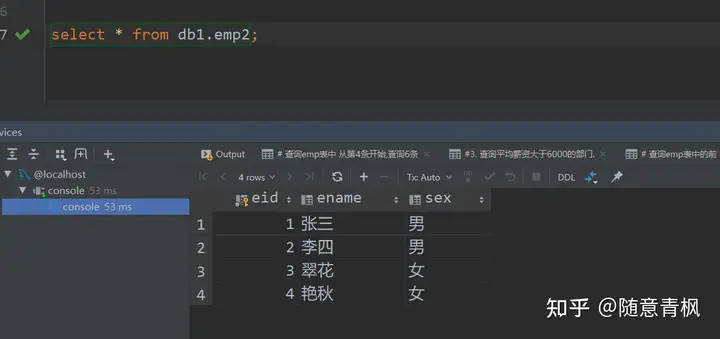
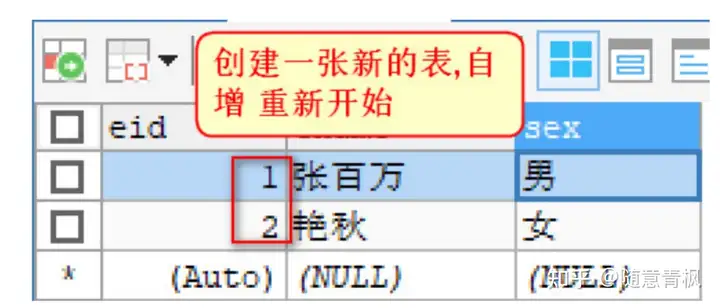
5)修改主键自增的起始值
默认地 AUTO_INCREMENT 的开始值是 1,如果希望修改起始值,请使用下面的方式
1 | -- 创建主键自增的表,自定义自增其实值 |
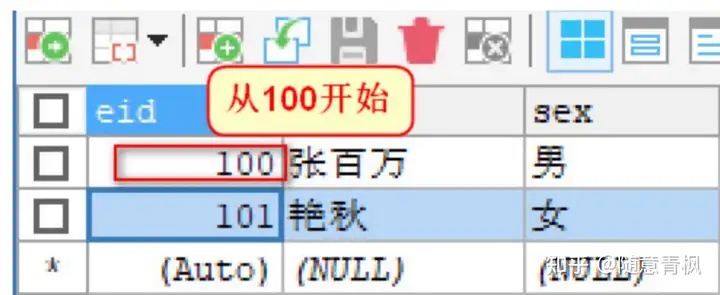
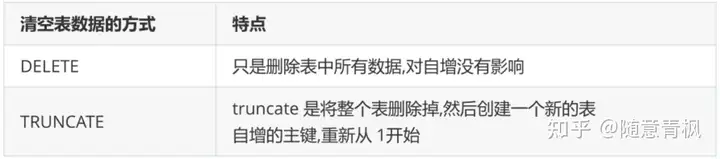
6)DELETE和TRUNCATE对自增长的影响
删除表中所有数据有两种方式
测试1: delete 删除表中所有数据
1 | -- 目前最后的主键值是 101 |
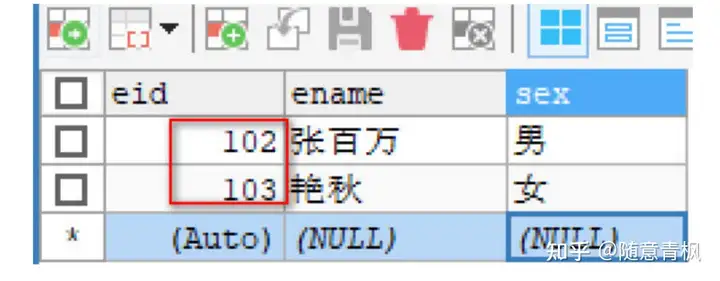
测试2: truncate删除 表中数据
1 | -- 使用 truncate 删除表中所有数据, |
5.2 非空约束
非空约束的特点:某⼀列不允许为空

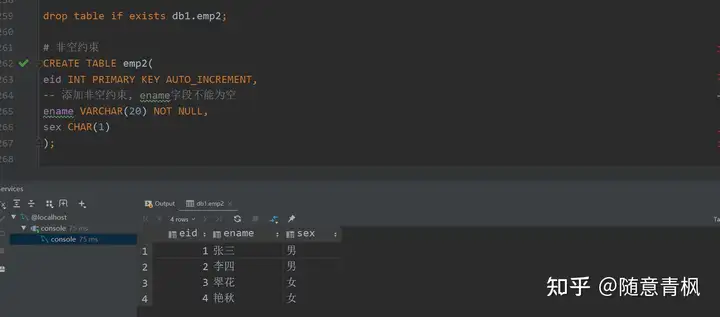
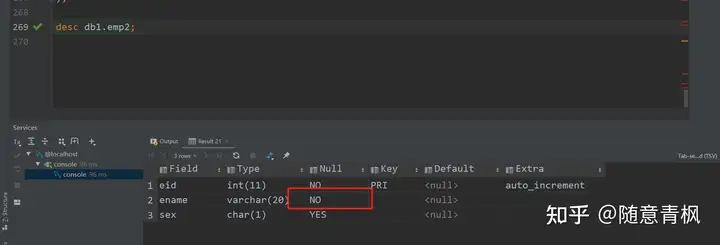
需求1: 为 ename 字段添加非空约束
1 | # 非空约束 |
5.3 唯一约束
唯一约束的特点: 表中的某一列的值不能重复( 对null不做唯一的判断 )

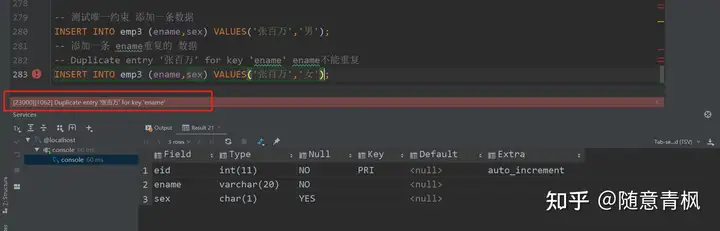
\1) 添加唯一约束
1 | #创建emp3表 为ename 字段添加唯一约束 |
\2) 测试唯一约束
1 | -- 测试唯一约束 添加一条数据 |
5.4 外键约束
FOREIGN KEY 表示外键约束,将在多表中学习。
5.5 默认值
默认值约束 用来指定某列的默认值

\1) 创建emp4表, 性别字段默认 女
1 | -- 创建带有默认值的表 |
\2) 测试 添加数据使用默认值
1 | -- 添加数据 使用默认值 |
六,多表查询
6.1 外键约束
主键:数据表A中有一列,这一列可以唯一的标识一条记录
外键:数据表A中有一列,这一列指向了另外一张数据表B的主键
1)什么是外键
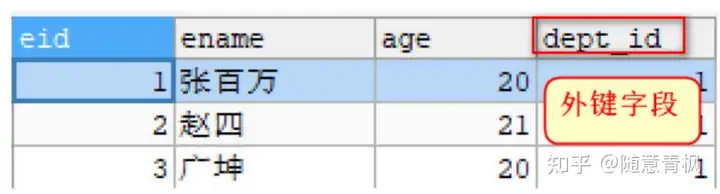
外键指的是在 从表 中 与 主表 的主键对应的那个字段,比如员工表的 dept_id,就是外键
使用外键约束可以让两张表之间产生一个对应关系,从而保证主从表的引用的完整性
多表关系中的主表和从表
主表: 主键id所在的表, 约束别人的表
从表: 外键所在的表多, 被约束的表
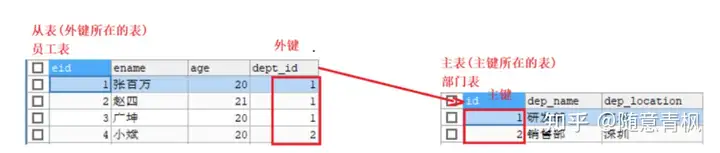
在上述的关系场景中,外键所在的表叫做从表,外键所指向的表叫做主表
2)创建外键约束
语法格式:
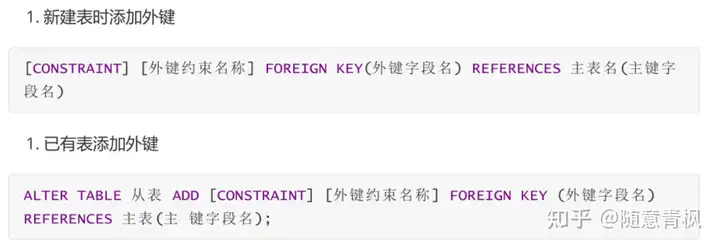
①重新创建employee表, 添加外键约束
1 | -- 先删除 employee表 |
①插入数据
1 | -- 正常添加数据 (从表外键 对应主表主键) |
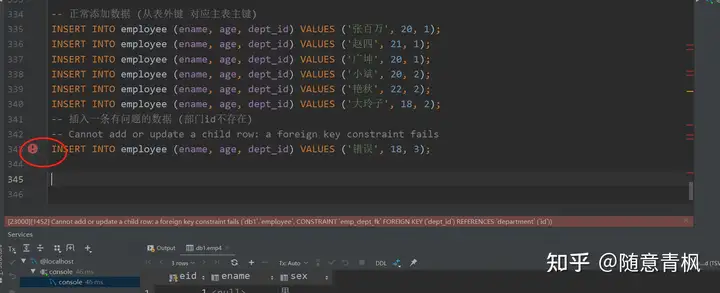
添加外键约束,就会产生强制性的外键数据检查, 从而保证了数据的完整性和一致性,
3)删除外键约束
添加/删除外键针对的都是从表
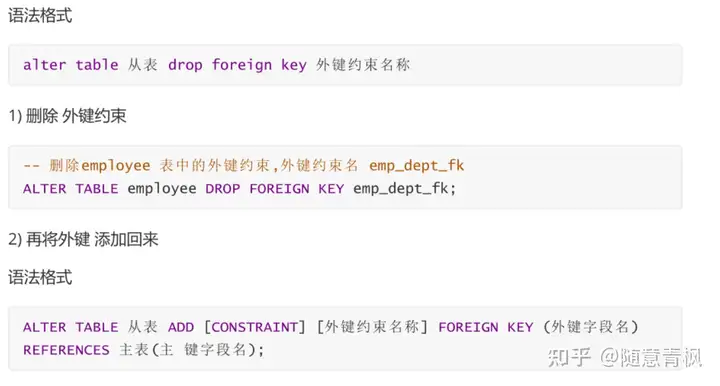

4)外键约束的注意事项
① 从表外键类型必须与主表主键类型一致 否则创建失败.

②添加数据时, 应该先添加主表中的数据
1 | -- 添加一个新的部门 |
③删除数据时,应该先删除从表中的数据.
1 | -- 删除数据时 应该先删除从表中的数据 |
5)级联删除操作(了解)
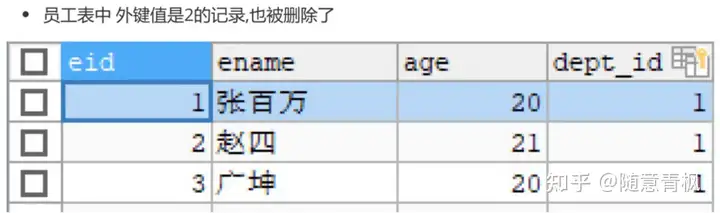
如果想实现删除主表数据的同时,也删除掉从表数据,可以使用级联删除操作

①删除 employee表,重新创建,添加级联删除
1 | drop table if exists employee; |
6.2 多表查询
\1) 创建db3_2 数据库
1 | -- 创建 db3_2 数据库,指定编码 |
\2) 创建分类表与商品表
1 | use db3_2; |
\3) 插入数据
1 | #分类数据 |
6.3 笛卡尔积
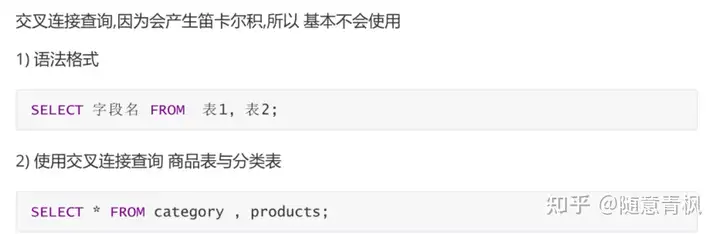

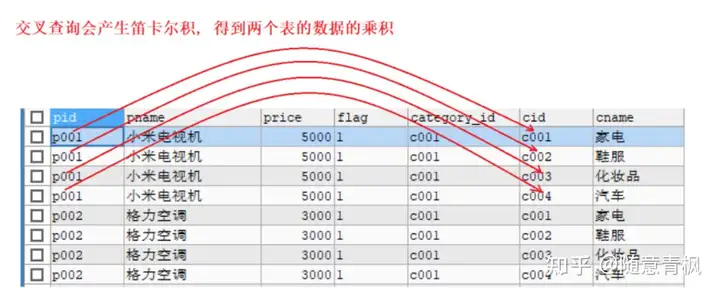
笛卡尔积
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1),
(b, 2)}。
SELECT 字段名 FROM 表1, 表2;
SELECT * FROM category , products;

笛卡尔积更进一步,添加where条件,过滤出有效数据
6.4 多表查询的分类
1)内连接查询
内连接的特点:
通过指定的条件去匹配两张表中的数据, 匹配上就显示,匹配不上就不显示
比如通过: 从表的外键 = 主表的主键 方式去匹配
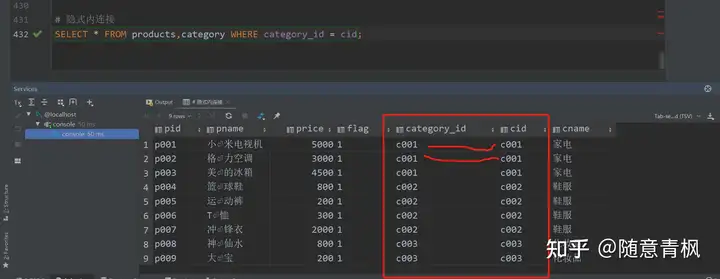
①隐式内链接
form子句 后面直接写 多个表名 使用where指定连接条件的 这种连接方式是 隐式内连接.
使用where条件过滤无用的数据
查询所有商品信息和对应的分类信息:
1 | # 隐式内连接 |
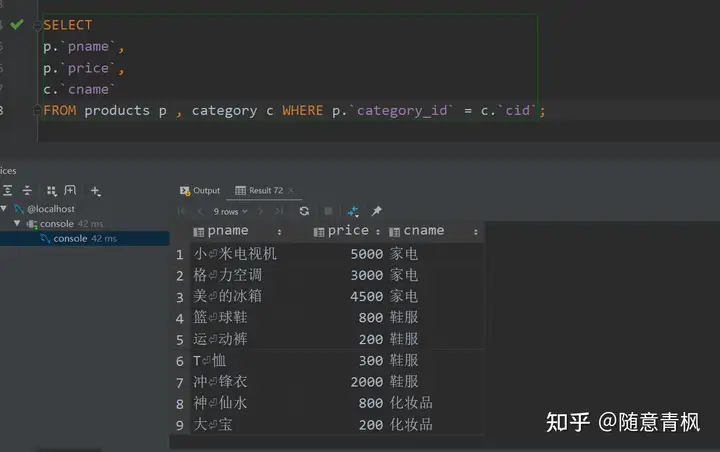
查询商品表的商品名称 和 价格,以及商品的分类信息
可以通过给表起别名的方式, 方便我们的查询(有提示)
1 | SELECT |
查询 格力空调是属于哪一分类下的商品
1 | #查询 格力空调是属于哪一分类下的商品 |
② 显式内连接
使用 inner join …on 这种方式, 就是显式内连接
查询所有商品信息和对应的分类信息
1 | # 显式内连接查询 |
查询鞋服分类下,价格大于500的商品名称和价格
1 | # 查询鞋服分类下,价格大于500的商品名称和价格 |
2) 外连接查询
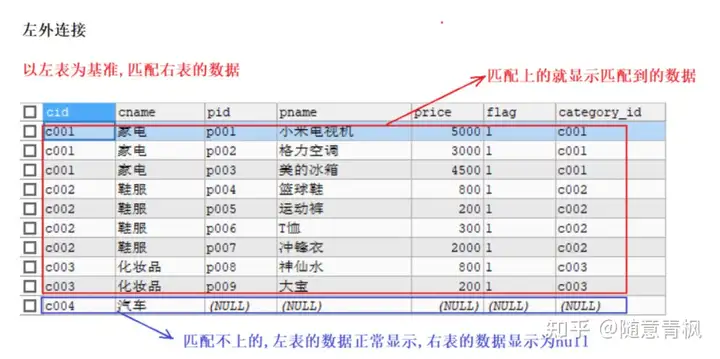
① 左外连接
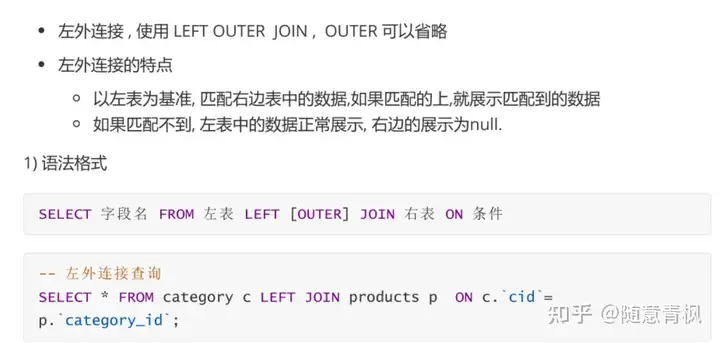

②右外连接
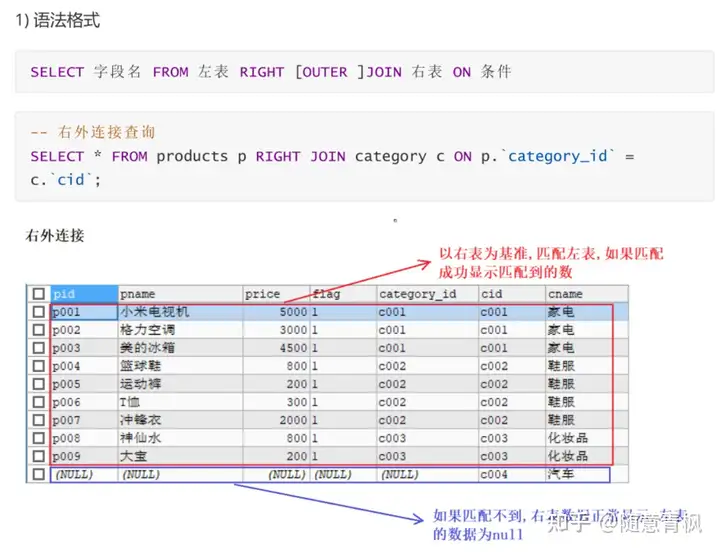
右外连接 , 使用 RIGHT OUTER JOIN , OUTER 可以省略
右外连接的特点
以右表为基准,匹配左边表中的数据,如果能匹配到,展示匹配到的数据
如果匹配不到,右表中的数据正常展示, 左边展示为null
3)各种连接方式的总结
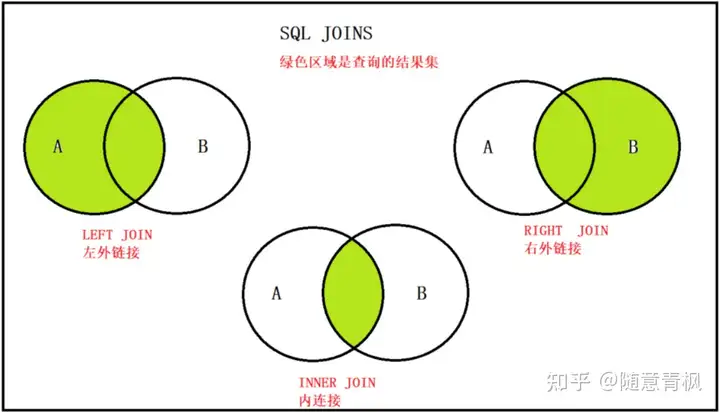
内连接: inner join , 只获取两张表中 交集部分的数据.
左外连接: left join , 以左表为基准 ,查询左表的所有数据, 以及与右表有交集的部分
右外连接: right join , 以右表为基准,查询右表的所有的数据,以及与左表有交集的部分
内连接和左外连接使用居多
6.5 合并查询
1)UNION
UNION 操作符用于合并两个或多个 SELECT 语句的结果集,并消除重复行。
注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同
时,每条 SELECT 语句中的列的顺序必须相同。
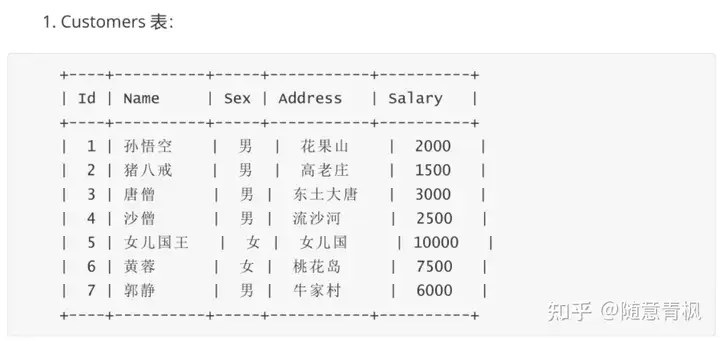
实列:
如下两张表
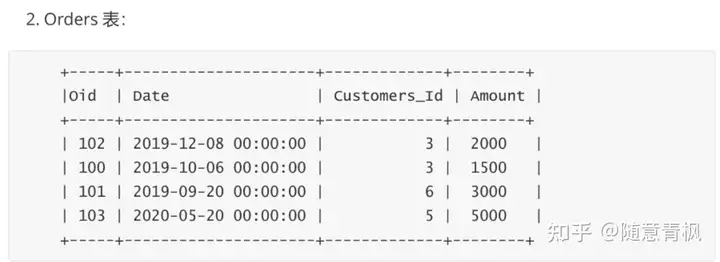
创建表
1 | CREATE TABLE Customers( |
插入数据
1 | INSERT INTO Customers (Name, Sex, Address, Salary) VALUES ('孙悟空', '男','花果山',2000); |
用 SELECT 语句将这两张表连接起来:
1 | SELECT Id,NAME,Amount,Date |
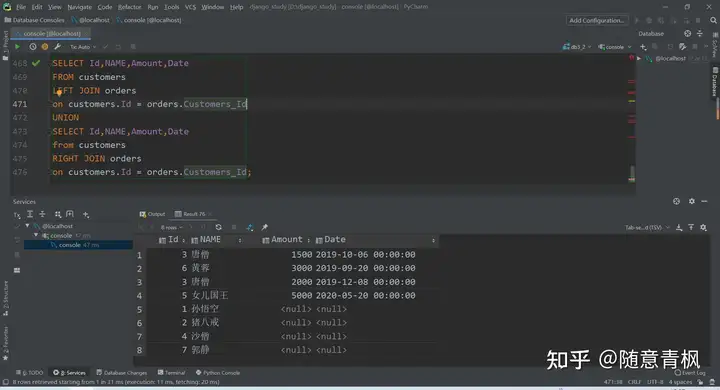
小结:
\1. 选择的列数必须相同;
\2. 所选列的数据类型必须在相同的数据类型组中(如数字或字符)
\3. 列的名称不必相同
\4. 在重复检查期间,NULL值不会被忽略
2)UNION ALL
UNION ALL 运算符用于将两个 SELECT 语句的结果组合在一起,重复行也包含在内。
UNION ALL 运算符所遵从的规则与 UNION 一致。
总结:
UNION和UNION ALL关键字都是将两个结果集合并为一个,也有区别。
1、重复值:UNION在进行表连接后会筛选掉重复的记录,而Union All不会去除重复记录。
2、UNION ALL只是简单的将两个结果合并后就返回。
3、在执行效率上,UNION ALL 要比UNION快很多,因此,若可以确认合并的两个结果集中不
包含重复数据,那么就使用UNION ALL。
6.6 子查询
1)什么是子查询

2)查询的结果作为查询条件
通过子查询的方式, 查询价格最高的商品信息
1 | # 通过子查询的方式, 查询价格最高的商品信息 |
查询化妆品分类下的 商品名称 商品价格
1 | #查询化妆品分类下的 商品名称 商品价格 |
查询小于平均价格的商品信息
1 | -- 1.查询平均价格 |
3)子查询的结果作为一张表
查询商品中,价格大于500的商品信息,包括 商品名称 商品价格 商品所属分类名称
1 | -- 1. 先查询分类表的数据 |
注意: 当子查询作为一张表的时候,需要起别名,否则无法访问表中的字段。
4)子查询结果是单列多行
子查询的结果类似一个数组, 父层查询使用 IN 函数 ,包含子查询的结果
语法格式
查询价格小于两千的商品,来自于哪些分类(名称)
1 | # 查询价格小于两千的商品,来自于哪些分类(名称) |
使用in函数, in( c002, c003 )
1 | -- 子查询获取的是单列多行数据 |
查询家电类 与 鞋服类下面的全部商品信息
1 | # 查询家电类 与 鞋服类下面的全部商品信息 |