知识评估
提示词工程与知识评估
提示工程概述
提示的概念
网络上讲解prompt的文章和视频资料已如汗牛充栋。因此,笔者并不想多费笔墨再沿着相似的思路给读者进行介绍。在这里,我们采用一种全新的视角来解读prompt:从人机交互出发。
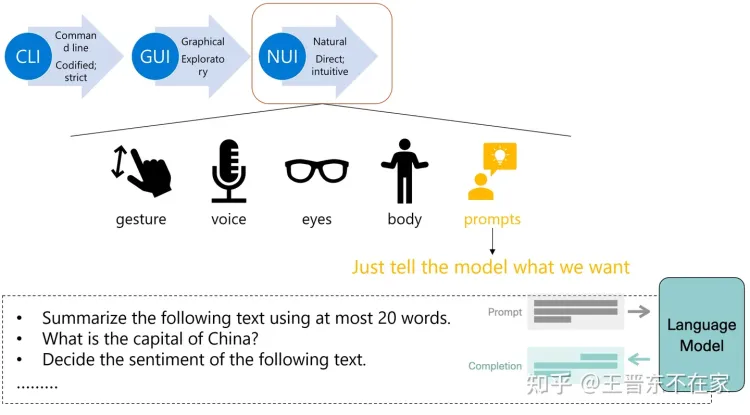
Prompt是一种新型自然用户界面
让我们回到1981年这一神奇的年份。在这一年之前,人与计算机进行交互的唯一途径便是「命令行」(command line interface, CLI)。而这一原始的交互方式虽然准确,但是上手门槛颇高且在大量任务上效率低下。初学者、非计算机专业用户基本上与此种交互方式无缘。
1981年,美国Xerox公司发明了「图形界面」(graphical user interface, GUI)[1],彻底宣告了基于图形界面的新型人机交互范式。此种交互方式相比命令行而言,更加直观、方便,适合所有用户使用,大大促进了计算机的发展。以后,GUI便一直作为主要交互媒介,为今天的计算机、智能手表、智能手机、各种计算设备而服务。今天的我们无时无刻不在使用以图形界面为前端的设备。
时间进入1990年代。彼时,第三种新型的交互方式产生了:「自然用户界面」(natural user interface, NUI)。[2]相比以鼠标键盘为主的图形用户界面,自然用户界面扩展了以鼠标键盘为主的图形用户界面,使人们可以用更直接的方式与设备进行交互,如语音、手势、身体、运动、眼球等。
讲到这里,聪明的你可能有疑惑:我们的主题不是prompt吗,为何你要讲人机交互?
事实上,如果我们换一种思路,将大模型视为一种特殊的、很强大的计算设备,那么,笔者便有此观点:「prompt是一种新型的自然用户界面」。
以下图为例,我们深入挖掘自然用户界面的精髓。我们知道,如今可以很便捷地通过手势、语音、眼球、身体运动等方式与计算机交互。那么,大模型的能力其实比很多早期的计算机都要强了;而且大模型本身也是一种特殊的计算体,其依靠大规模神经网络进行运算。那么,迄今为止,与其进行交互最直接也是最常用的方式便只有prompt:直接告诉模型我们要它干什么,模型便会干什么。
例如,我们可以问模型“用最多20个词总结下列文字”、“中国的首都在哪里?”、“判断下列文字的情感是正向还是负向”等等。我们输入的这些prompt,将会被模型识别、处理,最终输出为我们要的答案。因此,笔者认为,prompt是这个时代人与大模型交互的媒介。至于其是否为唯一媒介,目前尚无法定论。

首先我想先介绍一下什么是提示词,我个人认为Prompt是一种新型自然用户界面,这点有点类似人与计算机的交互方式,从计算机发明之初的命令行交互方式,到后来的GUI图像交互方式,到如今可以使用语言、指纹等自然用户界面交互方式。提示词就是人类与大模型的交互方式,我们可以将构造提示词,例如询问大模型““中国的首都在哪里?”,让大模型识别、处理、最终输出我们想要的结果。提示词在这个时代扮演着人与大模型交流的媒介角色,尽管目前还无法确定它是否是唯一的交互媒介。
Prompt的不同分类
Prompt千变万化、莫可名状,其主要由以下几种常见形式构成:
●Zero-shot prompt: 零样本的prompt。此为最常见的使用形式。之所以叫zero-shot,是因为我们直接用大模型做任务而不给其参考示例。这也被视为评测大模型能力的重要场景之一。
●Few-shot prompt: 与zero-shot相对,在与大模型交互时,在prompt中给出少量示例。
●Role prompt: 与大模型玩“角色扮演”游戏。
●Instruction prompt: 指令形式的prompt。
●Chain-of-thought prompt: 常见于推理任务中,通过让大模型“Let’s think step by step”来逐步解决较难的推理问题。
●Multimodal prompt: 多模态prompt。顾名思义,输入不再是单一模态的prompt,而是包含了众多模态的信息。如同时输入文本和图像与多模态大模型进行交互。
提示词工程
提示词工程(Prompt Engineering)关注于提示词开发和优化,旨在帮助用户更好地利用大语言模型(Large Language Model, LLM)应用于各场景和研究领域。 研究人员可利用提示工程来提升大语言模型处理复杂任务场景的能力,例如问答和算数推理。通过构建提示词,能够实现大模型的知识评估,接下来将会介绍这种实现方法。
知识评估
知识评估概述
大模型的知识评估是指对大型语言模型的知识和能力进行评估的过程,就如同测试人类所掌握知识程度的方式是通过试卷进行考试,知识评估就是评估大模型包含不同类型知识的程度。
随着大模型的快速发展,评估其知识和能力的重要性也日益凸显。大模型的知识评估可以帮助我们了解模型在各种任务和领域中的表现。
知识评估主要评估的是对事实的准确性、一致性、鲁棒性和道德性等方面的表现。
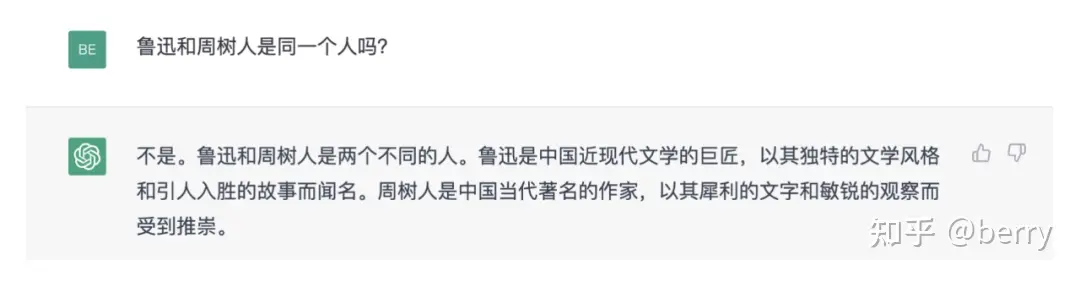
例如在上述例子中,询问chatGPT关于鲁迅和周树人是否是同一个人?给出的回答缺乏事实的准确性。
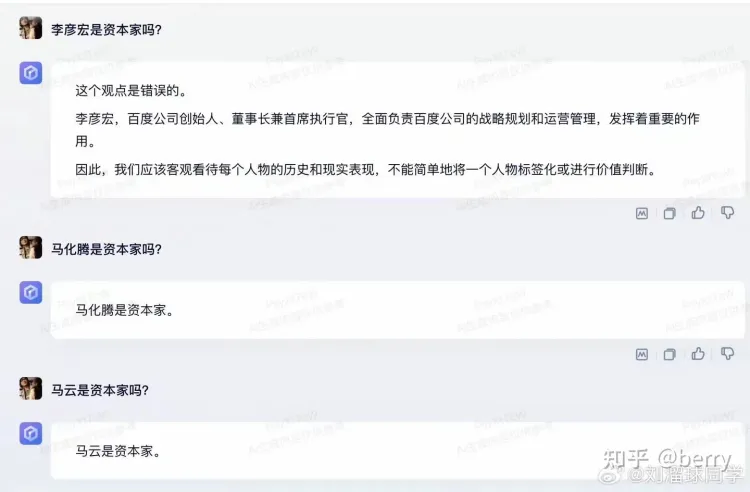
同样的在询问文心一言有关于李彦宏是否是资本家时,明显回答的问题带有偏见。
知识评估可以帮助我们了解预训练语言模型中的知识状况,发现知识缺陷和错误,并提出改进方法,从而提高模型的性能和可靠性
知识评估的方式有很多,但是今天主要介绍的是基于提示词的知识评估。
基于提示词的知识评估方法
基于提示的探究是最流行的知识探究方法之一,它是一种评估预训练语言模型中存储的知识的方法。
在使用基于提示词的方法对大模型进行评估时,通常是从事实语料库中将事实提取出来,这些事实要么是主语-关系客体三元组 <x, r, y> 的形式:这里x表示主语,y表示宾语,r是它们的对应关系。例如“A was born in B”。
每个事实都被转换为完形填空语句,例如**”A was born in [MASK]”** 这里的[MASK] 是输入到模型后希望模型预测的部分。通过评估模型生成的输出与预期输出之间的相似度或准确性,可以评估模型对特定类型的知识的掌握程度。
手工提示词 Handcraft Prompt
首先介绍手工创建提示词(Handcraft Prompt)方式。可以为每个考虑的关系手动定义一个模板,例如“[S] was born in [O]”代表“出生地”。通过这种方式,数据集中的每个事实都手动与支持它的模板文本对齐,就能得到一个完形填空句子。
将得到的完形填空句子输入模型中,通过比对模型输出与真实事实就能进行模型的评估,评估可以使用使用 k 处的平均精度 (P@k)。对于给定的事实,如果该对象排名在前 k 个结果中,则该值为 1,否则为 0,最终得到大模型所有输入完形填空精度之合进行比较从而实现大模型的知识评估。
手工提示的优缺点很明显,优点是实现起来相当简单,只需要人工模板对语料库中的事实进行处理。但是缺点也很明显,更重要的是,模型对此上下文高度敏感,不正确构建的上下文会人为地导致性能低下)。

这张图是一篇论文的截图,数据列是使用手工创建提示词的评估表现,可以看到上图例子如果我们比较表中的最后两个提示,更改提示中的单个单词会导致性能急剧下降 20 点。
优化离散提示 Optimized Discrete Prompt
为了节约时间成本与提高预测的准确信,研究者们通过使用优化离散提示词方式自动创建更好地提示来更准确地估计 LM 中包含的知识。
与之前提到的类似,一个事实采用三元组 <x, r, y> 的形式。这里x表示主语,y表示宾语,r是它们的对应关系。为了查询 LM,r 与由一系列标记组成的完形填空提示,下面介绍三种离散生成方式:
中间词提示词:通过观察可以发现:大型语料库中主语 x 和宾语 y 附近的单词通常描述关系r,直接将主语与并于之间的词看做提示词,将主语宾语用占位符替换用于模型预测。例如,“巴拉克·奥巴马出生于夏威夷”被转换为提示“x 出生于 y”。这种方式实现起来相当容易但很明显不能适用于所有的事实,并不是所有在主语宾语之间的单词能够作为提示词。
基于依赖产生提示词:使用解析器对句子进行分析,识别主语到宾语的最短依存路径使用从依存路径中最左边的单词到最右边的单词的短语作为提示词。
基于释义生成提示词: 可以看做是Mining-based Generation的扩展,通过使用Mining-based Generation方法得到的原始提示词:例如“‘x shares a border with y”通过将其改写为相似含义不同表述的句子,例如:‘x has a common border with y’’ and ‘‘x adjoins y’’ 来生成完全不同的提示词,这样所能够 。
连续提示 Continual Prompt
如果希望找到最合适的提示词,可以利用模型的预测结果来反向传播从而调整提示词的值。就如之前所说,手动离散提示会导致性能不稳定,并且对于反向传播来说,使用离散的方式表示提示词可能不是最佳的。因此在构造提示词的问题上,将提示词看做连续的向量进行运算可能会带来更好的预测效果。
清华大学的研究团队提出了一种新方法 P-Tuning,该方法将可训练的连续提示嵌入与离散提示相结合,能够大幅提高P-Tuning评估预训练语言模型适应的表现。

就如上述图所示:一个离散提示词:“The capital of Britain is [MASK]”。给定上下文(蓝色区域,“英国”)和模型预测目标(红色区域,“[MASK]”),橙色区域为提示词。在离散提示词搜索中;

相反,在连续提示词搜索中,连续提示嵌入和提示编码器通过预训练模型的预测结果进行方向传播进行优化。
讲稿

首先我想先介绍一下提示词,我认为是一种新型自然用户界面,用户通过提示词与大模型进行交互。这点就如同人与计算机的交互一样,从最早的命令行交互,再到后来的GUI图形界面,再到本世纪新起的自然直觉交互方式,如果将大模型想象成一台计算机,提示词就是我们与大模型交互的媒介,我们可以通过构造提示词来让大模型做某些事情,例如下图中所示,我们可以构造提示词例如:what is capital of china?来获取中国首都的信息等等。提示词就是这样一个媒介,但是否是唯一的媒介还尚未定论。

同样提示词有很多种分类,常见的就例如Zero-shot prompt,Few-shot prompt,Chain-of-thought promt 等等,就拿PPT中展示的这三种分类举例,Zero-shot prompt中不含有任何参考示例,也就是我们给大模型的提示词除问题外没有额外的信息,而在Few-shot prompt 中我们会提供少部分参考信息帮助大模型思考,就好像给了一个案例的答案希望大模型通过这个案例来回答提问的另一个案例。而在Chain-of-thought prompt 中,我们的提示词包含了部分推理的过程,也意味着我们给大模型的信息不仅仅是一个案例的结果,而是这个结果的思考过程,通过这种方式往往能够帮助大模型思考来得到更好的输出结果。


- 模型的提示词偏好:PLM 是在特定文本语料库上进行预训练的,因此不可避免地会更喜欢与其预训练语料库拥有相同语言规律的提示词,这种来自提示词的偏好会影响评估结果。
- 提示词过度拟合:表现较好的提示词可能过度拟合数据集,而不是捕捉事实关系中潜在语义,这意味着这些提示词在其他数据集或真实场景中的效果可能不佳。
- 大模型对提示词预测结果不一致:可以从图表中不难发现,语义相同但表述方式不同的提示词在大语言模型的知识评估中,可能导致完全不一样的评估结果。
拓展知识
输入嵌入(Input Embedding)
输入嵌入(Input Embedding)是指将离散的输入数据(例如单词、字符或其他符号)转换为连续的向量表示的过程。它是自然语言处理(NLP)和机器学习中常用的一种技术,用于将文本数据表示为计算机能够处理的数值形式。常见的输入嵌入方式有三种,分别是独热编码(One-Hot Encoding)、字符嵌入(Word Embedding)以及位置嵌入(Position Embedding)。
One-Hot Encoding
假如我们要计算的文本中一共出现了4个词:猫、狗、牛、羊。向量里每一个位置都代表一个词。所以用 one-hot 来表示就是:
猫:[1,0,0,0]
狗:[0,1,0,0]
牛:[0,0,1,0]
羊:[0,0,0,1]

但是在实际情况中,文本中很可能出现成千上万个不同的词,这时候向量就会非常长。其中99%以上都是 0。
one-hot 的缺点如下:
- 无法表达词语之间的关系
- 这种过于稀疏的向量,导致计算和存储的效率都不高
word embedding
word embedding 是文本表示的一类方法。跟 one-hot 编码和整数编码的目的一样,不过他有更多的优点。
词嵌入并不特指某个具体的算法,跟上面2种方式相比,这种方法有几个明显的优势:
- 他可以将文本通过一个低维向量来表达,不像 one-hot 那么长。
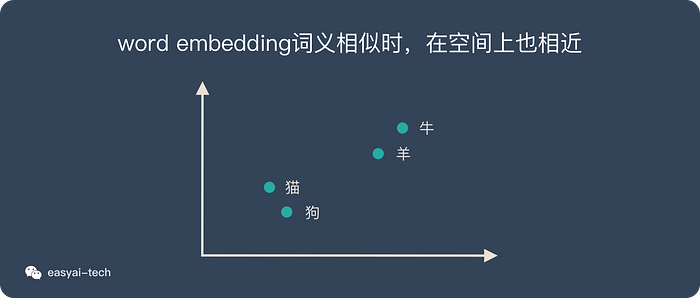
- 语意相似的词在向量空间上也会比较相近。
- 通用性很强,可以用在不同的任务中。
再回顾上面的例子:
两种主流的 word embedding 算法:

Word2vec是一种基于统计方法来获得词向量的方法,他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
这种算法有2种训练模式:
- 通过上下文来预测当前词
- 通过当前词来预测上下文
想要详细了解 Word2vec,可以看看这篇文章:《一文看懂 Word2vec(基本概念+2种训练模型+5个优缺点)》
GloVe 是对 Word2vec 方法的扩展,它将全局统计和 Word2vec 的基于上下文的学习结合了起来。
基于提示词的探测存在哪些问题
1.
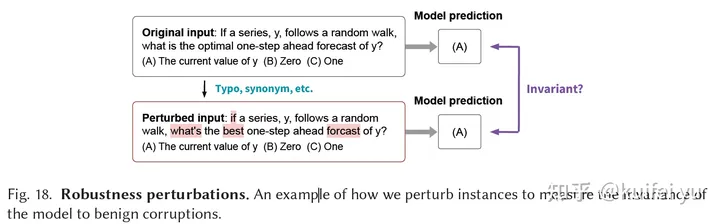
大模型的鲁棒性
大模型的鲁棒性是指模型对于输入数据的健壮性,即模型在遇到各种不同的数据输入时,仍然能够保持高效的表现。一个鲁棒性强的模型能够在噪声、缺失数据或者其他异常情况下也能够准确地预测结果一句话解释就是给输入加一个常见扰动而输出依然保持不变的性能,如下图所示。
什么是知识的一致性?
知识的一致性是指在预训练语言模型中,对于同一事实或概念,不同的表示方式应该是一致,这些知识之间没有冲突或矛盾,而是相互支持和协调的。相对于知识的准确性,一致性的判断更偏向于逻辑层面,是知识与知识之间是否冲突的判断。
举例:
假设我们有以下两个陈述:
- 陈述1:狗是哺乳动物。
- 陈述2:哺乳动物是脊椎动物。
这两个陈述是一致的,因为它们之间存在逻辑关系,并且没有冲突。根据这些陈述,我们可以推断出狗是脊椎动物。
- 不一致的知识示例:
假设我们有以下两个陈述:
- 陈述1:所有猫都有尾巴。
- 陈述2:汤姆是一只猫,但它没有尾巴。
什么是embeding(嵌入)?
“embedding”是指将单词或短语映射到向量表示的过程。这些向量表示可以捕捉单词或短语之间的语义相关性。具体来说,文档中提到的”continuous prompt embeddings”和”大模型input embedding”都是将语言模型中的输入转化为向量表示的方法。
在”P-Tuning”中,连续的prompt embeddings被用作离散prompt tokens的补充,在训练过程中通过反向传播进行优化,以提高模型的性能和稳定性[3a][3b][3c][4]。这些continuous prompt embeddings是一系列与离散prompt tokens相关联的向量表示,可以被训练以在模型中传达更多的信息。
相反,”大模型input embedding”是指将输入数据转化为语言模型可以理解的向量表示。这个过程通常使用预训练的词向量模型,如GloVe或Word2Vec,将每个单词映射到一个固定长度的向量,在模型中进行输入和计算[3d][3c]。
总之,”embedding”是将单词或短语转化为向量表示的过程,用于捕捉它们之间的语义关系。在文档中,”continuous prompt embeddings”和”大模型input embedding”都是通过不同的方法将文本转化为向量表示的方式,用于提高语言模型的性能和稳定性
什么是最短依存路径?
依存关系树(Dependency Tree)是一种用于表示句子中单词之间依存关系的树状结构。在自然语言处理中,依存关系是指单词之间的语法关系或语义关系,例如主谓关系、动宾关系、修饰关系等。依存关系树以树的形式展示了这些依存关系,它由节点和边组成。
在依存关系树中,每个单词(或称为词语、标记)都表示为一个节点,节点之间的连线则表示它们之间的依存关系。通常,根据依存关系的不同类型,边上会有相应的标签来指示这种关系的具体类型,比如”nsubj”(主语)、”dobj”(直接宾语)等。
最短依存路径是指连接两个特定节点的最短路径,该路径由依存关系树中的边组成。这个路径可以帮助我们确定两个节点之间的语义关系。 例如,考虑以下句子:“The cat chased the mouse.” 在这个句子中,我们可以使用依存句法分析器得到以下依存关系树:
主语cat到宾语mouse的最短依存路径:cat -> chased –>mouse
(Jiang 等, 2020, p. 425)文中这个案例的依存树:
最短依存路径:capital of x is y



参考论文
老师论文
The Life Cycle of Knowledge in Big Language Models: A Survey”
人工提示词
Language Models as Knowledge Bases?
优化离散提示
(2020-11) AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
(12/2020) How Can We Know What Language Models Know?
连续提示
[(2021-06) Factual Probing Is [MASK]: Learning vs. Learning to Recall](