Python学习笔记
Python运算符
算术运算符
以下假设变量: a=10,b=20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| // | 取整除 - 返回商的整数部分(向下取整) | >>> 9//2 4 >>> -9//2 -5 |
注意:Python2.x 里,整数除整数,只能得出整数。如果要得到小数部分,把其中一个数改成浮点数即可。
2
3
4
5
6
0
>>> 1.0/2
0.5
>>> 1/float(2)
0.5
比较运算符
以下假设变量a为10,变量b为20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True。 |
| <> | 不等于 - 比较两个对象是否不相等。**python3 已废弃。** | (a <> b) 返回 True。这个运算符类似 != 。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量 True 和 False 等价。 | (a < b) 返回 True。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 True。 |
赋值运算符
以下假设变量a为10,变量b为20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
注意:**Python 中没有 ++ 或 – 自运算符**
因为在 Python 里的数值和字符串之类的都是不可变对象,对不可变对象操作的结果都会生成一个新的对象。
比如:
2
a += 1在 C/java 之类的语言中,把 a 指向内存地址单元数据值由 1 改成了 2。
但是在 Python 中是完全不同的另一套机制。
解释器创建一个新的整数对象 2。
然后把这个对象的地址再次分配给 a。
见下面代码:
2
3
4
5
6
7
8
9
10
11
41116008L
>>> a = 1
>>> id(a)
41116008L
>>> id(2)
41115984L
>>>a += 1
>>> id(a)
41115984L
>>>所以在 Python 中不可能出现C/java 之类那种单独一行一个 i++,i– 的。
位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
下表中变量 a 为 60,b 为 13,二进制格式如下:
1 | a = 0011 1100 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1 。**~x** 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011,在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把”>>”左边的运算数的各二进位全部右移若干位,**>>** 右边的数字指定了移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔”与” - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔”或” - 如果 x 是非 0,它返回 x 的计算值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔”非” - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
Python中并没有&&、||、!逻辑符号
成员运算符
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
以下实例演示了Python所有成员运算符的操作:
1 | #!/usr/bin/python |
身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 **id(a) != id(b)**。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
注: id() 函数用于返回对象内存地址。
1 | #!/usr/bin/python |
以上实例输出结果:
1 | 1 - a 和 b 有相同的标识 |
不难发现,对于基础类型变量,使用=的赋值其实是传递右侧变量的引用,没有创建新的数据。
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。
2
3
4
5
6
7
8
9
10
11
>>> b = a
>>> b is a
True
>>> b == a
True
>>> b = a[:]
>>> b is a
False
>>> b == a
True主要:
b = a传递引用,而b = a[:]拷贝了列表a的值,产生了新的对象。
运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
Python程序控制符
if and else
Python程序语言指定任何非0和非空(null)值为true,0 或者 null为false。
Python 编程中 if 语句用于控制程序的执行,基本形式为:
1 | if 判断条件: |
其中”判断条件”成立时(非零),则执行后面的语句,而执行内容可以多行,以缩进来区分表示同一范围。
else 为可选语句,当需要在条件不成立时执行内容则可以执行相关语句。
Gif 演示:

具体例子如下:
实例
1 | #!/usr/bin/python |
输出结果为:
1 | luren # 输出结果 |
if 语句的判断条件可以用>(大于)、<(小于)、==(等于)、>=(大于等于)、<=(小于等于)来表示其关系。
当判断条件为多个值时,可以使用以下形式:
1 | if 判断条件1: |
1 | #!/usr/bin/python |
输出结果:
1 | roadman # 输出结果 |
注意:由于 python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现,如果判断需要多个条件需同时判断时,可以使用 or (或),表示两个条件有一个成立时判断条件成功;使用 and (与)时,表示只有两个条件同时成立的情况下,判断条件才成功。
for
for循环的语法格式如下:
1 | for iterating_var in sequence: |
1 | #!/usr/bin/python |
以上实例输出结果:
1 | 当前字母: P |
while
Python 编程中 while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务。其基本形式为:
1 | while 判断条件(condition): |
执行语句可以是单个语句或语句块。判断条件可以是任何表达式,任何非零、或非空(null)的值均为true。
当判断条件假 false 时,循环结束。
1 | #!/usr/bin/python |
以上代码执行输出结果:
1 | The count is: 0 |
while 语句时还有另外两个重要的命令 continue,break 来跳过循环,continue 用于跳过该次循环,break 则是用于退出循环,此外”判断条件”还可以是个常值,表示循环必定成立.
在 python 中,while … else 在循环条件为 false 时执行 else 语句块:
1 | #!/usr/bin/python |
以上实例输出结果为:
1 | 0 is less than 5 |
Pass
Python pass 是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
Python 语言 pass 语句语法格式如下:
1 | pass |
测试实例:
1 | #!/usr/bin/python |
以上实例执行结果:
1 | 当前字母 : P |
在 Python 中有时候会看到一个 def 函数:
1 | def sample(n_samples): |
该处的 pass 便是占据一个位置,因为如果定义一个空函数程序会报错,当你没有想好函数的内容是可以用 pass 填充,使程序可以正常运行。
Python变量及其操作
Python有五个标准的数据类型:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
可以使用del语句删除一些 对象引用。
del语句的语法是:
1 | del var1[,var2[,var3[....,varN]]]] |
可以通过使用del语句删除单个或多个对象,例如:
1 | del var |
Number(数字)
Number类型
Python 支持四种不同的数值类型:
- 整型(Int) - 通常被称为是整型或整数,是正或负整数,不带小数点。
- 长整型(long integers) - 无限大小的整数,整数最后是一个大写或小写的L。
- 浮点型(floating point real values) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x $10^2$ = 250)。
- 复数(complex numbers) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
数字函数汇总
math 模块、cmath 模块
Python 中数学运算常用的函数基本都在 math 模块、cmath 模块中。
cmath 模块的函数跟 math 模块函数基本一致,区别是 cmath 模块运算的是复数,math 模块运算的是数学运算。
要使用 math 或 cmath 函数必须先导入:
1 | import math,cmath |
查看 math 查看包中的内容:
1 | import math |
查看 cmath 查看包中的内容
1 | import cmath |
实例
1 | import cmath |
数学函数
| 函数 | 返回值 ( 描述 ) |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| cmp(x, y) | 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| fabs(x) | 以浮点数形式返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,…) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,…) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 |
| pow(x, y) | x**y 运算后的值。 |
| [round(x ,n]) | 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 |
| sqrt(x) | 返回数字x的平方根 |
随机数函数
随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。
Python包含以下常用随机数函数:
| 函数 | 描述 |
|---|---|
| choice(seq) | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 |
| [randrange (start,] stop [,step]) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 |
| random() | 随机生成下一个实数,它在[0,1)范围内。 |
| [seed(x]) | 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。 |
| shuffle(lst) | 将序列的所有元素随机排序 |
| uniform(x, y) | 随机生成下一个实数,它在[x,y]范围内。 |
三角函数
| 函数 | 描述 |
|---|---|
| acos(x) | 返回x的反余弦弧度值。 |
| asin(x) | 返回x的反正弦弧度值。 |
| atan(x) | 返回x的反正切弧度值。 |
| atan2(y, x) | 返回给定的 X 及 Y 坐标值的反正切值。 |
| cos(x) | 返回x的弧度的余弦值。 |
| hypot(x, y) | 返回欧几里德范数 sqrt(xx + yy)。 |
| sin(x) | 返回的x弧度的正弦值。 |
| tan(x) | 返回x弧度的正切值。 |
| degrees(x) | 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0 |
| radians(x) | 将角度转换为弧度 |
数学常量
| 常量 | 描述 |
|---|---|
| pi | 数学常量 pi(圆周率,一般以π来表示) |
| e | 数学常量 e,e即自然常数(自然常数)。 |
String(字符串)
索引与切片
python的字串列表有2种取值顺序:
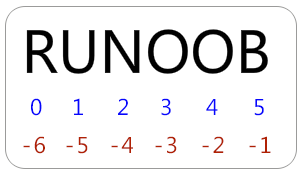
- 从左到右索引默认0开始的,最大范围是字符串长度少1
- 从右到左索引默认-1开始的,最大范围是字符串开头
如果你要实现从字符串中获取一段子字符串的话,可以使用 [头下标:尾下标:步长] 来截取相应的字符串,即**[start:stop:step]**。其中 start 表示起始索引,stop 表示结束索引(不包含在结果中),step 表示步长(可选,默认为1)。注意,切片操作是左闭右开的,即起始索引处的元素包含在结果中,但结束索引处的元素不包含在结果中。当我们将切片参数省略时,Python会使用默认值:start=0,stop=len(obj),step=1。因此,obj[::]代表选择整个对象。
比如:
1 | >>> s = 'abcdef' |
当使用以冒号分隔的字符串,python 返回一个新的对象,结果包含了以这对偏移标识的连续的内容,左边的开始是包含了下边界。
上面的结果包含了 s[1] 的值 b,而取到的最大范围不包括尾下标,就是 s[5] 的值 f。

加号(+)是字符串连接运算符,星号(*)是重复操作。如下实例:
1 | #!/usr/bin/python |
以上实例输出结果:
1 | Hello World! |
Python 列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串:
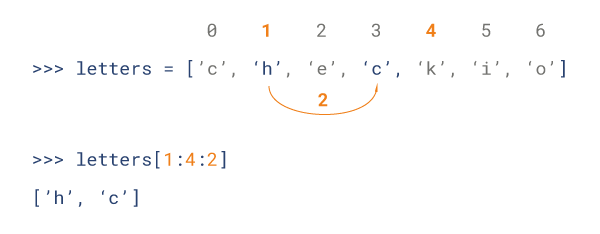
特殊情况下,步长可以为负数,为负数时代表截取从后向前遍历,这意味着它会以相反的顺序返回切片范围内的元素。
例如:
1 | s = "1234567" |
1 | 76543 |
遍历从6到1,此时下标为1的’2’无法被取到。
字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
如下实例:
1 | #!/usr/bin/python |
以上实例输出结果:
1 | My name is Zara and weight is 21 kg! |
python 字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
三引号
Python 中三引号可以将复杂的字符串进行赋值。
Python 三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
三引号的语法是一对连续的单引号或者双引号(通常都是成对的用)。
1 | >>> hi = '''hi |
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的。
一个典型的用例是,当你需要一块HTML或者SQL时,这时当用三引号标记,使用传统的转义字符体系将十分费神。
1 | errHTML = ''' |
字符串内建函数
这些方法实现了 string 模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对 Unicode 的支持,有一些甚至是专门用于 Unicode 的。
| 方法 | 描述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| string.decode(encoding=’UTF-8’, errors=’strict’) | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 ‘ignore’ 或 者’replace’ |
| string.encode(encoding=’UTF-8’, errors=’strict’) | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| string.isnumeric() | 如果 string 中只包含数字字符,则返回 True,否则返回 False |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False. |
| string.istitle() | 如果 string 是标题化的(见 title())则返回 True,否则返回 False |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.lstrip() | 截掉 string 左边的空格 |
| string.maketrans(intab, outtab) | maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.partition(str) | 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
| string.rfind(str, beg=0,end=len(string) ) | 类似于 find() 函数,返回字符串最后一次出现的位置,如果没有匹配项则返回 -1。 |
| string.rindex( str, beg=0,end=len(string)) | 类似于 index(),不过是返回最后一个匹配到的子字符串的索引号。 |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.rpartition(str) | 类似于 partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除 string 字符串末尾的空格. |
| string.split(str=””, num=string.count(str)) | 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+1 个子字符串 |
| [string.splitlines(keepends]) | 按照行(‘\r’, ‘\r\n’, ‘\n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
| [string.strip(obj]) | 在 string 上执行 lstrip()和 rstrip() |
| string.swapcase() | 翻转 string 中的大小写 |
| string.title() | 返回”标题化”的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| string.translate(str, del=””) | 根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.zfill(width) | 返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
List(列表)
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 [ ] 标识,是 python 最通用的复合数据类型。
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。
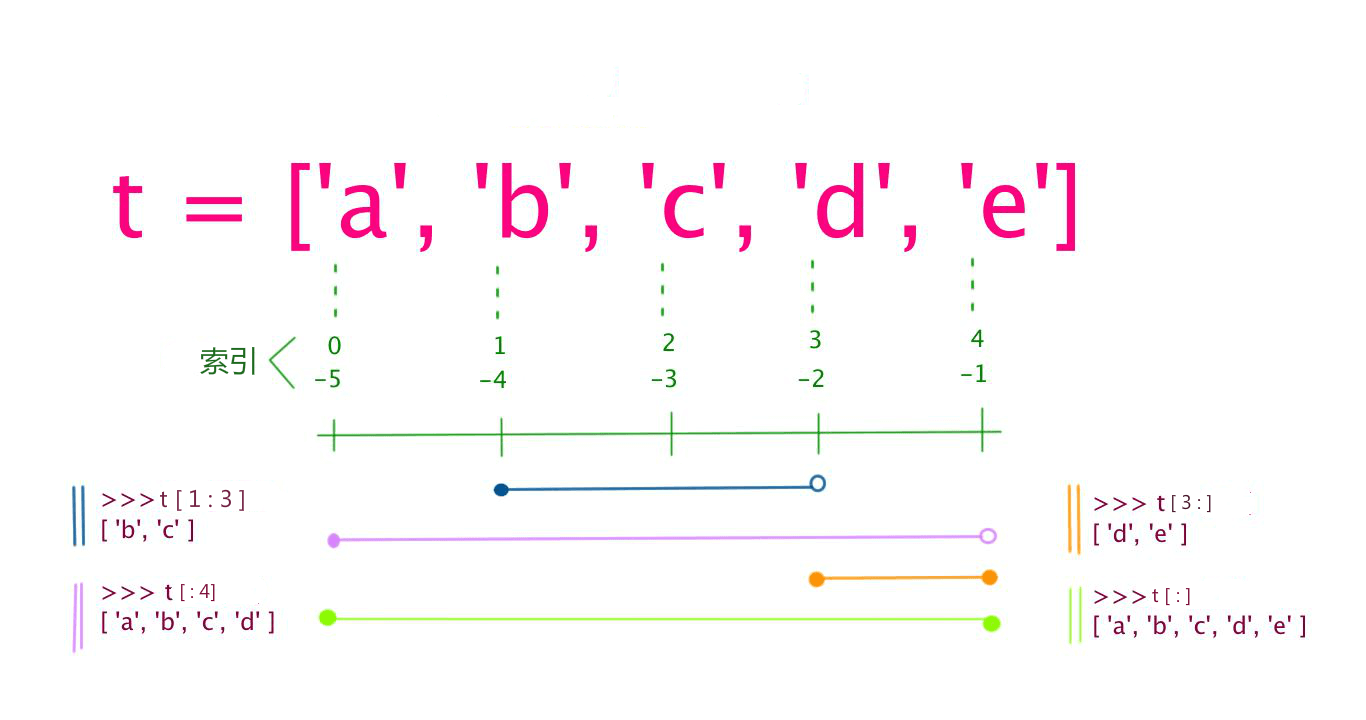
删除列表元素
可以使用 del 语句来删除列表的元素,如下实例:
1 | #!/usr/bin/python |
以上实例输出结果:
1 | ['physics', 'chemistry', 1997, 2000] |
列表函数&方法
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2) 比较两个列表的元素 |
| 2 | len(list) 列表元素个数 |
| 3 | max(list) 返回列表元素最大值 |
| 4 | min(list) 返回列表元素最小值 |
| 5 | list(seq) 将元组转换为列表 |
Python包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | [list.pop([index=-1])](https://www.runoob.com/python/att-list-pop.html) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False) 对原列表进行排序 |
Tuple(元组)
元组是另一个数据类型,类似于 List(列表)。
元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
如下实例:
1 | tup1 = ('physics', 'chemistry', 1997, 2000) |
创建空元组
1 | tup1 = () |
元组中只包含一个元素时,需要在元素后面添加逗号
1 | tup1 = (50,) |
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,组合后的元组会新分配空间,如下实例:
1 | #!/usr/bin/python |
以上实例输出结果:
1 | (12, 34.56, 'abc', 'xyz') |
注意:通过
+实现元组切片时,需要符号两侧元素均为元组,这点与列表相同。例如:
(1,2,3) + (1)会报错,因为(1)并非一个元组而是一个数字,正确的写法是:(1,2,3) + (1,)再比如下面这个例子:
2
3
4
5
6
7
8
9
c=a[1:4]+a[5] # 报错, a[5] 被当成了整型
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate tuple (not "int") to tuple
c=a[1:4]+a[2:4] # 这样可以
c
(2, 3, 4, 3, 4)
a[5]截取的是一个数字,如果需要截取到一个元组,正确的截取方法是:a[5:6]或a[5:]
删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
1 | #!/usr/bin/python |
以上实例元组被删除后,输出变量会有异常信息,输出如下所示:
1 | ('physics', 'chemistry', 1997, 2000) |
元组内置函数
| 序号 | 方法及描述 |
|---|---|
| 1 | cmp(tuple1, tuple2) 比较两个元组元素。 |
| 2 | len(tuple) 计算元组元素个数。 |
| 3 | max(tuple) 返回元组中元素最大值。 |
| 4 | min(tuple) 返回元组中元素最小值。 |
| 5 | tuple(seq) 将列表转换为元组。 |
Dictionary(字典)
**字典(dictionary)**是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典用”{ }”标识。字典由索引(key)和它对应的值value组成。字典的每个键值 key:value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
1 | d = {key1 : value1, key2 : value2 } |
删除字典元素
显示删除一个字典用del命令,如下实例:
1 | #!/usr/bin/python |
但这会引发一个异常,因为用del后字典不再存在:
1 | tinydict['Age']: |
字典键值的特性
字典值可以没有限制地取任何 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
字典键两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
1 | #!/usr/bin/python |
1 | tinydict['Name']: Manni |
2)键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行,如下实例:
1 | #!/usr/bin/python |
1 | Traceback (most recent call last): |
字典内置函数&方法
Python字典包含了以下内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | cmp(dict1, dict2) 比较两个字典元素。 |
| 2 | len(dict) 计算字典元素个数,即键的总数。 |
| 3 | str(dict) 输出字典可打印的字符串表示。 |
| 4 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys(seq[, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 注:使用[]访问字典不存在的键会报错,而dict.get()方法不会 |
| 5 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false 注:python3中已经移除,改为使用 in 和 not in 判断键是否在字典中 |
| 6 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys() 以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 以列表返回字典中的所有值 |
| 11 | pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值。 |
Python数据类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。
| 函数 | 描述 |
|---|---|
| int(x [,base]) | 将x转换为一个整数 |
| long(x [,base] ) | 将x转换为一个长整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个序列 (key,value)元组。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| unichr(x) | 将一个整数转换为Unicode字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
Python函数
定义一个函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号**()**。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
例如下面这个函数的定义与调用:
1 | def writeAndAdd(s): |
1 | 传入字符串: 123 |
DocStrings 文档字符串是一个重要工具,用于解释文档程序,帮助你的程序文档更加简单易懂。
2
3
4
5
6
7
8
9
# -*- coding: UTF-8 -*-
def function():
''' say something here!
'''
pass
print (function.__doc__) # 调用 docDocStrings 文档字符串使用惯例:它的首行简述函数功能,第二行空行,第三行为函数的具体描述。
更多内容可参考:Python 文档字符串(DocStrings)
参数传递
Python 在 heap 中分配的对象分成两类:可变对象和不可变对象。所谓可变对象是指,对象的内容是可变的,例如 list。而不可变的对象则相反,表示其内容不可变。
1 | 不可变对象 :int,string,float,tuple -- 可理解为C中,该参数为值传递 |
不可变对象
由于 Python 中的变量存放的是对象引用,所以对于不可变对象而言,尽管对象本身不可变,但变量的对象引用是可变的。运用这样的机制,有时候会让人产生糊涂,似乎可变对象变化了。如下面的代码:
1 | i = 73 |

从上面得知,不可变的对象的特征没有变,依然是不可变对象,变的只是创建了新对象,改变了变量的对象引用。
不可变对象的参数传递类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
看看下面的代码,更能体现这点的。
1 | #!/usr/bin/python |
可变对象
其对象的内容是可以变化的。当对象的内容发生变化时,变量的对象引用是不会变化的。如下面的例子。
1 | m=[5,9] |

可变对象的参数传递类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
1 | #!/usr/bin/python |
实例中传入函数的和在末尾添加新内容的对象用的是同一个引用,故输出结果如下:
1 | 函数内取值: [10, 20, 30, [1, 2, 3, 4]] |
参数
必备参数
必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
调用printme()函数,你必须传入一个参数,不然会出现语法错误:
1 | #!/usr/bin/python |
以上实例输出结果:
1 | Traceback (most recent call last): |
关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
1 | #!/usr/bin/python |
以上实例输出结果:
1 | Name: miki |
默认参数
调用函数时,默认参数的值如果没有传入,则被认为是默认值。下例会打印默认的age,如果age没有被传入:
1 | #!/usr/bin/python |
输出结果:
1 | Name: miki |
不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。基本语法如下:
1 | def functionname([formal_args,] *var_args_tuple ): |
加了星号(*)的变量名会存放所有未命名的变量参数。不定长参数实例如下:
1 | #!/usr/bin/python |
以上实例输出结果:
1 | 输出: |
注意:函数内部的不定长参数会被当做tuple类型,即使只传入一个参数,例如下面这个例子:
2
3
4
5
6
7
8
9
10
11
12
def function1(*var1):
data1 = (1,)
print(operator.eq(var1,data1))
def function2(*var2):
data2 = (1,2)
print (operator.eq(data2,var2))
function1(1)
function2(1, 2)
2
3
True
True
匿名函数
python 使用 lambda 来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda函数的语法只包含一个语句,如下:
1 | lambda [arg1 [,arg2,.....argn]]:expression |
如下实例:
1 | #!/usr/bin/python |
以上实例输出结果:
1 | 相加后的值为 : 30 |
变量作用域
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序你可以访问哪个特定的变量名称。两种最基本的变量作用域如下:
- 全局变量
- 局部变量
全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。如下实例:
1 | #!/usr/bin/python |
以上实例输出结果:
1 | 函数内是局部变量 : 30 |
函数内部使用全局变量
全局变量想作用于函数内,需加 global
1 | #!/usr/bin/python |
1、global—将变量定义为全局变量。可以通过定义为全局变量,实现在函数内部改变变量值。
2、一个global语句可以同时定义多个变量,如 global x, y, z。
模块导入
系统自带的模块
以正则表达式模块为例,我们经常这样写代码:
1 | import re |
但有时候,你可能会看到某些人这样写代码:
1 | from re import search |
那么这两种导入方式有什么区别呢?
我们分别使用type函数来看看他们的类型:
1 | import re |
如下图所示:
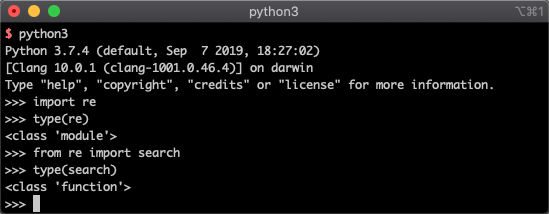
可以看到,直接使用import re导入的re它是一个module类,也就是模块。我们把它成为正则表达式模块。而当我们from re import search时,这个search是一个function类,我们称呼它为search 函数。
一个模块里面可以包含多个函数。
如果在你的代码里面,你已经确定只使用search函数,不会再使用正则表达式里面的其他函数了,那么你使用两种方法都可以,没什么区别。
但是,如果你要使用正则表达式下面的多个函数,或者是一些常量,那么用第一种方案会更加简洁清晰。
例如:
1 | import re |
在这个例子中,你分别使用了re.search,re.sub,re.S和re.I。后两者是常量,用于忽略换行符和大小写。
但是,如果你使用from re import search, sub, S, I来写代码,那么代码就会变成这样:
1 | import re |
看起来虽然简洁了,但是,一旦你的代码行数多了以后,你很容易忘记S和I这两个变量是什么东西。而且我们自己定义的函数,也很有可能取名为sub或者search,从而覆盖正则表达式模块下面的这两个同名函数。这就会导致很多难以觉察的潜在 bug。
再举一个例子。Python 的 datetime模块,我们可以直接import datetime,此时我们导入的是一个datetime模块,如下图所示:
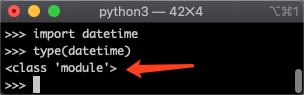
但是如果你写为from datetime import datetime,那么你导入的datetime是一个type类:
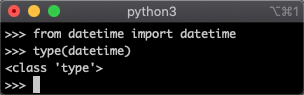
因为这种方式导入的datetime,它就是Python 中的一种类型,用于表示包含日期和时间的数据。
这两种导入方式导入的datetime,虽然名字一样,但是他们的意义完全不一样,请大家观察下面两种写法:
1 | import datetime |
1 | from datetime import datetime, timedelta |
第二种写法看似简单,但实则改动起来却更为麻烦。例如我还需要增加一个变量today用于记录今日的日期。
对于第一段代码,我们只需要增加一行即可:
today = datetime.date.today()
但对于第二行来说,我们需要首先修改导入部分的代码:
from datetime import datetime, timedelta, date
然后才能改代码:today = date.today()
这样一来你就要修改两个地方,反倒增加了负担。
第三方库
在使用某些第三方库的代码里面,我们会看到类似这样的写法:
1 | from lxml.html import fromstring |
但是我们还可以写为:
1 | from lxml import html |
但是,下面这种写法会导致报错:
1 | import lxml |
那么这里的lxml.html又是什么东西呢?
这种情况多常见于一些特别大型的第三方库中,这种库能处理多种类型的数据。例如lxml它既能处理xml的数据,又能处理html的数据,于是这种库会划分子模块,lxml.html模块专门负责html相关的数据。
自己来实现多种导入方法
我们现在自己来写代码,实现这多种导入方法。
我们创建一个文件夹DocParser,在里面分别创建两个文件main.py和util.py,他们的内容如下:
util.py文件:
1 | def write(): |
main.py文件:
1 | import util |
运行效果如下图所示:
现在我们把main.py的导入方式修改一下:
1 | from util import write |
依然正常运行,如下图所示
当两个文件在同一个文件夹下面,并且该文件夹里面没有init.py 文件时,两种导入方式等价。
现在,我们来创建一个文件夹microsoft,里面再添加一个文件parse.py:
1 | def read(): |
如下图所示:
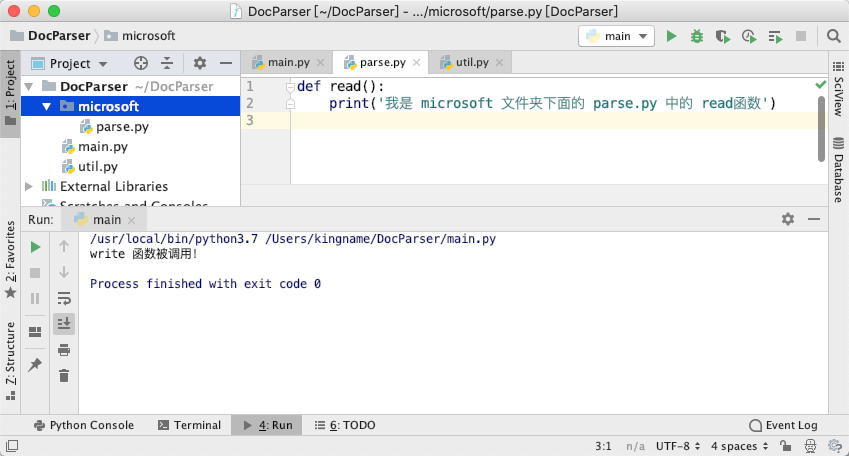
此时我们在 main.py中对它进行调用:
1 | from microsoft import parse |
运行效果如下图所示:
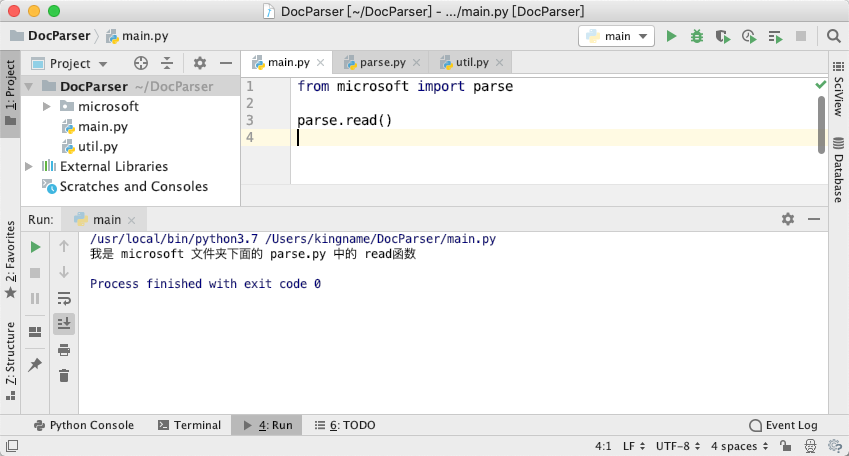
我们也可以用另一种方法:
1 | from microsoft.parse import read |
运行效果如下图所示:
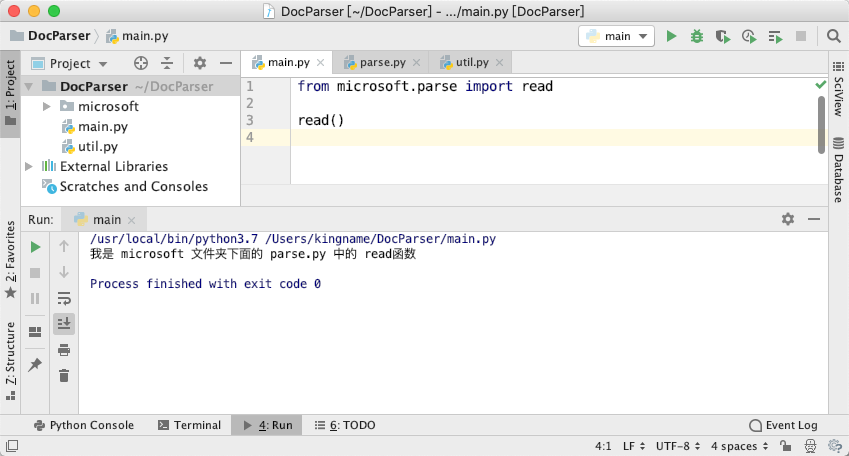
但是,你不能直接导入microsoft,如下图所示:
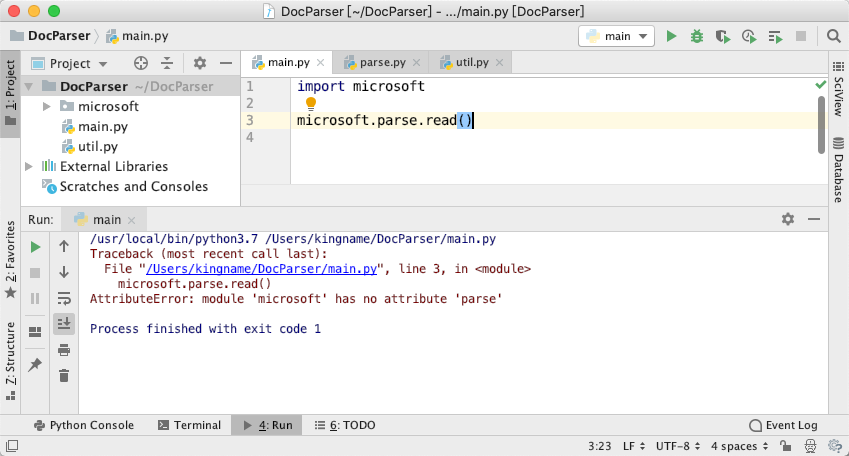
你只能导入一个模块或者导入一个函数或者类,你不能导入一个文件夹
无论你使用的是import xxx还是from xxx.yyy.zzz.www import qqq,你导入进来的东西,要不就是一个模块(对应到.py 文件的文件名),或者是某个.py 文件中的函数名、类名、变量名。
无论是import xxx还是from xxx import yyy,你导入进来的都不能是一个文件夹的名字。
可能有这样一种情况,就是某个函数名与文件的名字相同,例如:
在 microsoft文件夹里面有一个microsoft.py文件,这个文件里面有一个函数叫做microsoft,那么你的代码可以写为:
from microsoft import microsoft`microsoft.microsoft()
但请注意分辨,这里你导入的还是模块,只不过microsoft.py文件名与它所在的文件夹名恰好相同而已。
而对于上级目录,可以使用下面的方式导入:
1 | --|A |
Python异常处理
标准异常
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
异常处理
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
1 | try: |
try的工作原理是,当开始一个try语句后,python就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。
- 如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。
- 如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印默认的出错信息)。
- 如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
面是简单的例子,它打开一个文件,在该文件中的内容写入内容,但文件没有写入权限,发生了异常:
1 | #!/usr/bin/python |
再执行以上代码:
1 | $ python test.py |
注意:不要在 try 里写返回值。 try-except-else 里都是指做某事,而不是处理返回。如果在 try 里面写返回值,则 else 部分是 unreachable 的。
你也可以使用相同的except语句来处理多个异常信息,如下所示:
1 | try: |
你可以不带任何异常类型使用except来捕获所有的异常,如下实例:
1 | try: |
finnaly关键字
try-finally 与 Java 中类似,语句无论是否发生异常都会执行finally中的语句,如下面这个例子:
1 | #!/usr/bin/python |
1 | $ python test.py |
触发异常
我们可以使用raise语句自己触发异常
raise语法格式如下:
1 | raise [Exception [, args [, traceback]]] |
语句中 Exception 是异常的类型(例如,NameError)参数标准异常中任一种,args 是自已提供的异常参数。
最后一个参数是可选的(在实践中很少使用),如果存在,是跟踪异常对象。
一个异常可以是一个字符串,类或对象。 Python的内核提供的异常,大多数都是实例化的类,这是一个类的实例的参数。
1 | try: |
1 | #!/usr/bin/python |
执行以上代码,输出结果为:
1 | $ python test.py |
用户自定义异常
通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。
以下为与RuntimeError相关的实例,实例中创建了一个类,基类为RuntimeError,用于在异常触发时输出更多的信息。
在try语句块中,用户自定义的异常后执行except块语句,变量 e 是用于创建Networkerror类的实例。
1 | class Networkerror(RuntimeError): |
在你定义以上类后,你可以触发该异常,如下所示:
1 | try: |
Python面向对象
类及其结构
使用 class 语句来创建一个新类,class 之后为类的名称并以冒号结尾:
1 | class ClassName: |
以下是一个简单的 Python 类的例子:
1 | #!/usr/bin/python |
属性
属性访问
上例中,empCount 变量是一个类变量,它的值将在这个类的所有实例之间共享。可以在内部类或外部类使用 employee对象.empCount 访问。
也可以使用下面函数的方式来访问属性:
- getattr(obj, name[, default]) : 访问对象的属性。
- hasattr(obj,name) : 检查是否存在一个属性。
- setattr(obj,name,value) : 设置一个属性。如果属性不存在,会创建一个新属性。
- delattr(obj, name) : 删除属性。
1 | hasattr(emp1, 'age') # 如果存在 'age' 属性返回 True。 |
内置属性
在Python中,一个类中默认存在内置类属性,如下所示:
__dict__: 类的属性(包含一个字典,由类的数据属性组成)__doc__: 类的文档字符串__name__: 类名__module__:类定义所在的模块,(类的全名是__main__.className,如果类位于一个导入模块mymod中,那么className.__module__等于 mymod)__bases__: 类的所有父类构成元素(包含了一个由所有父类组成的元组)
Python内置类属性调用实例如下:
1 | #!/usr/bin/python |
执行以上代码输出结果如下:
1 | Employee.__doc__: 所有员工的基类 |
公有、私有、保护属性
public_attrs:没有下划线开头,声明该属性为公有,可以在类内部、外部均可被访问。
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
_protect_attrs:以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *
方法
类方法
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self(当然这个名称并非固定)
1 | class Test: |
以上实例执行结果为:
1 | <__main__.Test instance at 0x10d066878> |
与属性类似,两个下划线开头**__private_method**,声明该方法为私有方法,不能在类的外部调用。在类的内部调用 self.__private_methods。
基础重载方法
第一种方法__init__()方法是一种特殊的方法,被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法,Python的类中还有下面的基础重载方法:
| 序号 | 方法, 描述 & 简单的调用 |
|---|---|
| 1 | init ( self [,args…] ) 构造函数 简单的调用方法: obj = className(args) |
| 2 | del( self ) 析构方法, 删除一个对象 简单的调用方法 : del obj |
| 3 | repr( self ) 转化为供解释器读取的形式 简单的调用方法 : repr(obj) |
| 4 | str( self ) 用于将值转化为适于人阅读的形式 简单的调用方法 : str(obj) |
| 5 | cmp ( self, x ) 对象比较 简单的调用方法 : cmp(obj, x) |
从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.__class__ 则指向类。
创建类的实例对象
实例化类其他编程语言中一般用关键字 new,但是在 Python 中并没有这个关键字,类的实例化类似函数调用方式。
以下使用类的名称 Employee 来实例化,并通过__init__方法接收参数。
1 | "创建 Employee 类的第一个对象" |
类的继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
继承语法
1 | class 派生类名(基类名,...) |
在python中继承中的一些特点:
- 在调用基类的方法时,需要加上基类的类名前缀,且需要带上 self 参数变量。区别在于类中调用普通函数时并不需要带上 self 参数
- Python 总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
对于子类继承父类构造函数说明:
情况一:子类需要自动调用父类的方法:子类不重写__init__()方法,实例化子类后,会自动调用父类的__init__()的方法。
情况二:子类不需要自动调用父类的方法:子类重写__init__()方法,实例化子类后,将不会自动调用父类的__init__()的方法。
情况三:子类重写__init__()方法又需要调用父类的方法:使用super关键词:
1 | super(子类,self).__init__(参数1,参数2,....) |
如果在继承元组中列了一个以上的类,那么它就被称作”多重继承” 。
语法:
派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示:
1 | class SubClassName (ParentClass1[, ParentClass2, ...]): |
1 | #!/usr/bin/python |
以上代码执行结果如下:
1 | 调用子类构造方法 |
你可以继承多个类
1 | class A: # 定义类 A |
你可以使用issubclass()或者isinstance()方法来检测。
- issubclass() - 布尔函数判断一个类是另一个类的子类或者子孙类,语法:issubclass(sub,sup)
- isinstance(obj, Class) 布尔函数如果obj是Class类的实例对象或者是一个Class子类的实例对象则返回true。